이번 글에서는 Spark 에서 Shuffle 데이터를 관리하는 방법인 External Shuffle Service 와 Remote Shuffle Service에 대해서 자세히 살펴보자.
1. ESS 와 RSS
Spark는 groupBy, join, repartition 같은 연산은 모두 셔플을 유발하게 된다.
Map 태스크가 셔플 데이터를 로컬 디스크에 쓰고 Reduce 태스크가 가져가는데, 핵심은
이 셔플 파일을 누가 서빙하느냐이다.
기본 동작에서는 Executor 프로세스가 직접 서빙하므로, Executor가 죽거나 동적 할당으로 회수되면 셔플 데이터도 사라져 재연산이 발생하게 된다.
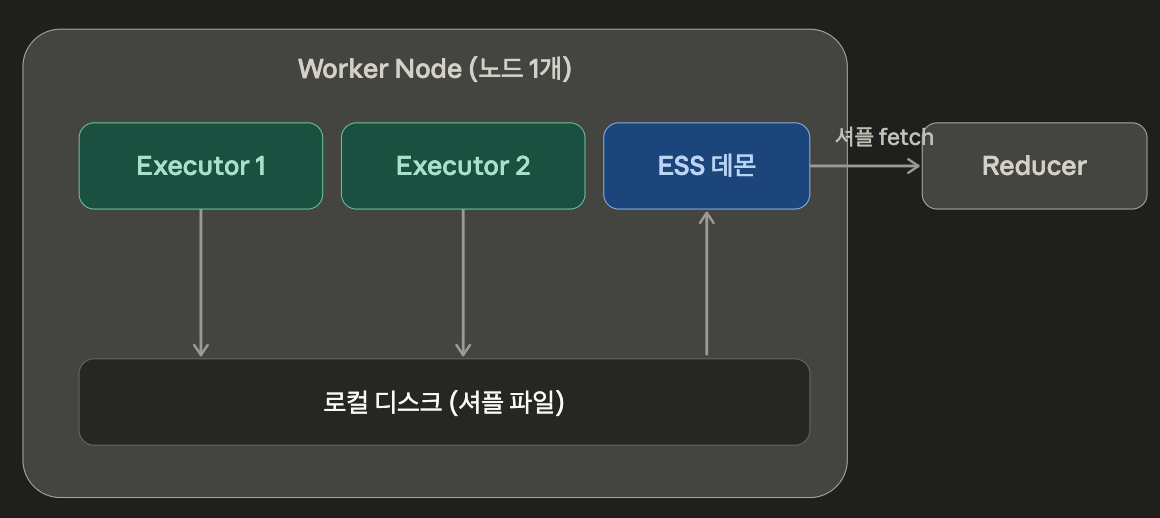
ESS 는 각 셔플 서빙을 Executor와 분리된 별도 데몬으로 옮긴 것이다.
YARN 에서는 NodeManager 프로세스 안에 service로 탑재되어 동작하며, Executor가 회수, 종료되어도 노드의 ESS가 셔플 데이터를 계속 서빙한다.
덕분에 동적 할당이 가능해지며, 핵심은 ESS가 Executor당 하나가 아니라 노드당 하나이며, 그 노드의 모든 Executor가 공유하고 있어서 Executor가 죽거나 회수되어도 같은 노드의 ESS가 그 셔플 파일을 계속 서빙할 수 있다.
ESS 는 Spark가 실행되는 노드(Worker Node) 마다 하나씩 떠 있는 노드 단위 데몬이다. NodeManager 자체는 모든 Worker node에 존재한다.
spark.shuffle.service.enabled=true ## ESS
spark.dynamicAllocation.enabled=true
spark.dynamicAllocation.shuffleTracking.enabled=false
한계는 분명하다. 셔플 데이터가 여전히 Map 태스크가 돌았던 노드의 로컬 디스크에 남아 노드 장애시 유실될 수 있고, 대규모 셔플에서 병목이 된다.
대규모 셔플에서 병목이 발생하는 이유는 M x R 랜덤 읽기 방식으로 진행되기 때문이다.
전통적인 Spark 셔플에서는 각 Mapper가 자기 출력을 R개의 파티션으로 쪼개서 디스크에 쓴다.
즉, Mapper 하나가 R개의 블록을 만들고, Mapper가 M개니까 셔플 블록은 총 M x R개가 된다.
문제는 읽는 쪽이다. 각 Reducer는 자기 파티션 하나를 완성하려고 모든 M개 Mapper로 부터 작은 블록을 하나씩 끌어와야 한다.
이 블록들은 여러 노드, 여러 파일에 잘게 흩어져 있어서, 디스크를 sequential I/O 가 아니라 여기저기를 건너뛰며 읽는 random I/O가 되며, 랜덤 읽기는 특히 순차 읽기 보다 훨씬 느리다.
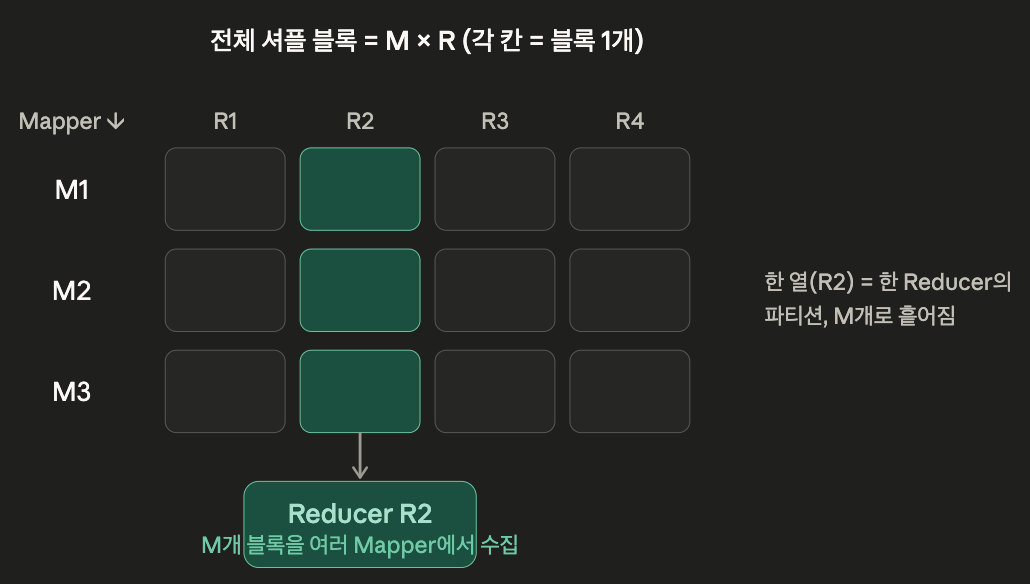
Reduce가 R 개니까 전체로는 M x R 번의 작은 fetch 가 발생하게 되며, 규모가 커질 수록 병목이 발생한다. Spark 3.2 부터 YARN에서도 이러한 한계를 해결하기 위해 Push-based Shuffle(Magnet) 를 제공한다.
RSS 는 셔플 데이터를 컴퓨팅 노드 밖의 전용 원격 클러스터로 분리한다.
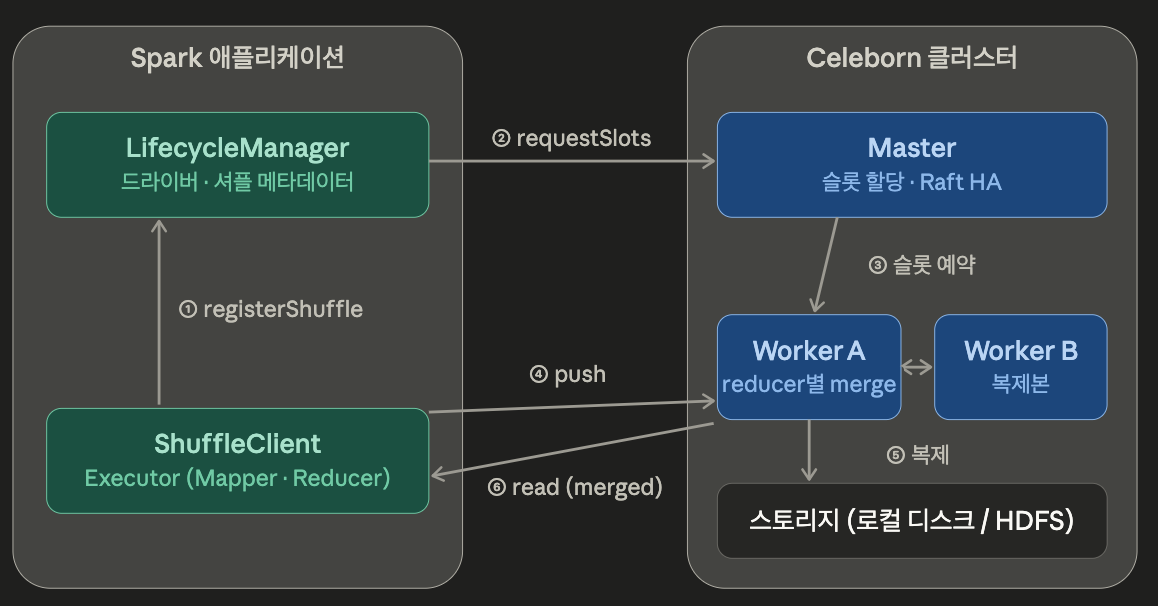
매퍼가 원격 서버로 push 하면 서버가 파티션 단위로 취합, 복제하고 리듀서는 큰 블록을 순차 읽기로 가져간다.
대표적인 구현체는 Apache Celeborn과 Apache Uniffle 이 존재한다.
현재 Apache Celeborn 을 사용하고 있기 때문에 이를 기준으로 설명한다.
Celeborn 은 Master, Worker, Client 세 컴포넌트로 구성되며, Master는 모든 리소스를 관리하고 공유상태를 동기화하고, Worker는 read-write 요청을 처리하며 Reducer 별로 데이터를 병합한다.
spark.shuffle.manager=org.apache.spark.shuffle.celeborn.SparkShuffleManager
spark.shuffle.service.enabled=false # ESS 비활성화
spark.dynamicAllocation.shuffleTracking.enabled=false
spark.celeborn.client.spark.shuffle.fallback.policy=NEVER
YARN 온프레미스에서 동적 할당이 필요하면 ESS가 사실상 표준이지만, Kubernetes에는 이런 노드 단위 ESS가 기본 제공되지 않기 때문에 RSS를 사용할 수 있다.
spark.dynamicAllocation.shuffleTracking 은 Spark 3.0 부터 도입된 방식으로 셔플 데이터를 가진 Executor를 추적해서, 그 데이터가 더 필요 없어질 때까지 회수를 막는 방식이다.
즉, ESS, RSS 에서 제공하는 DRA가 아닌 Spark 기본 동적할당(DRA)을 쓰기 위한 대체 수단이다.
Celeborn 문서를 보면 spark.dynamicAllocation.shuffleTracking.enabled=false를 강하게 권장하고 있고, spark 3.5.0 이상에서는 아래와 같이 Celeborn이 DRA 지원 기능을 직접 제공한다.
spark.shuffle.sort.io.plugin.class org.apache.spark.shuffle.celeborn.CelebornShuffleDataIO
ESS, RSS 모두 셔플 데이터를 서빙하는 주체가 Executor가 아니기 때문에 Executor를 회수해도 셔플 데이터가 살아남고 동적할당이 가능하기에 해당 옵션은 불필요하다.
2. ESS 와 RSS 의 장단점
2-1) ESS
ESS 장점
- Executor 생명주기와 셔플 서빙이 분리되어 동적할당이 가능하다. 즉, Executor가 GC, 회수되어도 같은 노드의 ESS가 셔플 파일을 계속 서빙할 수 있다.
- Spark/YARN 생태계에 기본 내장되어 있어 별도 클러스터 운영이 불필요하다. 운영 부담이 가장 적고 가장 검증된 표준이다.
- 노드당 데몬 하나를 모든 Executor가 공유하고, 로컬 디스크에서 직접 서빙하므로 가볍다.
ESS 단점
- Executor 손실은 막지만 노드/디스크 손실은 막지 못해서, 노드가 죽으면 그 셔플은 유실되고 재연산이 필요하다.
- 데이터가 커질수록 디스크 I/O 병목이 되고, 대규모 셔플에서 성능, 안정성이 떨어진다.
- 워커 노드의 디스크 용량, 대역폭에 의존하므로 디스크 압박이 생긴다.
- 특히, YARN에서는 NodeManager JVM 안에서 돌기 때문에 셔플 부하가 크면 NodeManager의 heap GC에 영향을 준다.
2-2) RSS
RSS 장점
- 셔플을 컴퓨팅 노드 밖으로 완전히 분리되며, replication로 내결함성을 확보할 수 있다.
- 워커 노드 장애 시에도 재연산을 피할 수 있어서 ESS의 노드 손실 한계를 극복할 수 있다.
- 메모리, HDFS, S3 등 다양한 스토리지 계층을 지원하고, 대규모 셔플 잡을 처리할 수 있다.
RSS 단점
- 별도 클러스터(Master, Worker) 운영, 관리 부담이 존재한다.
- replication을 켜면 에트워크, 저장 비용과 쓰기 부하가 늘고, Worker가 하나뿐이면 복제 자체가 불가하다.
- 원격 서비스 자체가 새로운 병목이 될 수 있기 때문에, Master HA, Worker 확장을 제대로 설계해야 한다.
- 추가 네트워크를 사용하기 때문에 작은 셔플, 경량 워크로드에는 오히려 오버헤드일 수 있다.
Reference
https://blog.banksalad.com/tech/spark-on-kubernetes/
https://justkode.kr/data-engineering/spark-on-k8s-1/
https://techblog.woowahan.com/10291/
https://spot.io/blog/setting-up-managing-monitoring-spark-on-kubernetes/
https://aws.amazon.com/ko/blogs/containers/optimizing-spark-performance-on-kubernetes/