이번글에서는 Spark on Yarn 에서 Spark on K8s로 전환 과정에서 발생한 이슈를 정리해 보려고 한다.
1. 현재 구조
현재 Spark 를 Kubernetes 에서 실행시키기 위한 구조는 Airflow 를 통해 트리거가 되며, Spark Submit 하기 위해 KubernetesPodOperator를 이용하여 실행하고 있다.
- Deploy Mode: Cluster
- Spark Version: 3.4.4 (Pyspark)
- Airflow Version: 3.1.8
전반적인 실행 흐름은 아래와 같다.
[Airflow Scheduler]
└─ KubernetesPodOperator 트리거
│
▼
[Worker Pod] ← KubernetesPodOperator가 생성하는 Pod
└─ spark-submit 실행
│
▼
[Spark Driver Pod] → [Spark Executor Pods]
│
Job 완료 → Driver: Completed
│
▼
Worker Pod 종료 → Airflow Task: Success
KPO Pod 내의 Python에서 외부 프로그램(spark submit 등)을 실행하기 위한 모듈인 subprocess.Popen()을 사용하여 spark submit 을 진행하고 있다.
with subprocess.Popen([
"/opt/spark/bin/spark-submit",
"--master", "k8s://kubernetes",
"--conf", "spark.kubernetes.submission.waitAppCompletion=true",
"script.py"
], stdout=subprocess.PIPE, stderr=subprocess.STDOUT, text=True) as process:
즉, spark submit을 별도의 python subprocess로 실행하며, 그 하위 subprocess 로 java 를 실행하여 관리하게 된다.
$ ps -ef
UID PID PPID CMD
root 1 0 /usr/bin/tini --
root 7 1 python3 spark_submit_job py
root 37 7 java ... org.apache.spark.deploy.SparkSubmit ...
Pyspark 를 사용하기 때문에 위와 같이 Python과 Java 프로세스가 나뉘어서 실행되며, Java 프로세스가 Driver Pod 생성 요청 및 모니터링 등의 역할을 담당한다.
또한, Kubernetes 환경에서 Airflow를 돌리고 있다면 KubernetesExecutor와 KubernetesPodOperator 두가지 방법 중 선택할 것이며, 현재 환경은 KubernetesPodOperator를 사용하여 실행하고 있다.
KubernetesExecutor와 KubernetesPodOperator(KPO)의 차이는 결국 Executor와 Operator의 차이이다.
Operator는 Task가 무엇을 할지 정한다. 예시로는 PythonOperator, BashOperator, MysqlOperator 등이 있다.
각각 Operator는 이름 그대로 Python 스트립트를 실행, Bash 스크립트를 실행, Mysql 에서 sql query를 실행해준다.
2. Driver Pod는 종료되었지만 KPO Pod는 종료되지 않는 이슈
2-1) Root Cause
Airflow 의 KubernetesPodOperator(KPO)를 이용하여 spark submit 을 하기 때문에 spark submit 이후 spark 어플리케이션이 정상적으로 실행 및 종료된 다음 Airflow Task를 종료 시켜야 한다.
따라서, spark.kubernetes.submission.waitAppCompletion=true 옵션을 이용하여 Spark 어플리케이션의 상태를 모니터링 하도록 하였다.
이 옵션을 활성화하게 되면 driver pod에 watch api를 호출해서 driver pod가 완료되기까지 KPO pod의 spark submit 프로세스가 이를 대기한다.
watch api란 kubernetes 리소스의 상태 변화를 실시간으로 모니터링하기 위한 메커니즘이며, 서버가 클라이언트로 상태를 전달해주는 단방향 구조이다.
즉, http 요청과는 다르게 연결을 계속 유지하며, 상태가 변경될 때마다 이벤트를 전송한다.
만약, watch api 연결 이후 세션 만료 등 다양한 이유로 connection이 종료되면 마지막 resourceVersion 기준으로 다시 연결을 시도하게 된다.
하지만 간헐적으로 아래와 같이 driver pod는 실행이 완료되어 정상적으로 completed 상태가 되었지만 KPO Pod는 종료되지 않는 이슈가 확인되었다.
LoggingPodStatusWatcherImpl: Waiting for application..to finish
Application status..phase: Running
WARN: Watch ConnectionManager: Exec Failure: HTTP 401 Unauthorized.
현재 Airflow 가 실행되는 K8s Cluster와 Spark 가 실행되는 K8s Cluster는 다른 클러스터를 사용하고 있으며, Fabric8 Kubernetes Client 를 함께 사용하면서 문제가 발생함을 확인했다.
Fabric8 버전은 6.4.1 을 사용하고 있다.
Fabric8 Kubernetes Client 란 Java로 작성된 Kubernetes API 클라이언트 라이브러리이며, Spark는 Kubernetes Cluster에 작업을 제출할 때 Fabric8을 사용한다.
Airflow 에서 KPO Pod가 실행되고, Spark 전용 클러스터에 실행하기 위한 인증 토큰을 아래와 같이 옵션으로 전달해주게 된다.
# remote k8s master endpoint 통신을 위한 인증서
--conf spark.kubernetes.authenticate.submission.caCertFile=/opt/airflow/remote-k8s/ca.crt
# service account token
--conf spark.kubernetes.authenticate.submission.oauthTokenFile=/opt/airflow/remote-k8s/token
watch api를 이용한 연결 이후 네트워크 순단 등의 이유로 connection이 종료되었을 때, reconnect 를 시도하는 과정에서 문제가 발생한다.
spark submit 할때 명시적으로 전달한 토큰 값이 아닌, 현재 클러스터의 토큰값을 찾아서 덮어씌워버린다.
https://github.com/fabric8io/kubernetes-client/issues/2271 를 참고해보면 6.1.0 부터 /var/run/secrets/kubernetes.io/serviceaccount/token 파일을 재로드시 자동으로 로드하도록 변경 된 것을 확인하였다.
Fabric8 Kubernetes Client 에서 Config.java 코드에서 확인할 수 있으며, spark submit 할 때 명시적으로 전달한 토큰 값을 사용하는게 아니라, 클러스터 내에 내장된 토큰 값을 기본 값으로 사용하게 된다.
즉, 재시도를 할 때도 동일하게 Spark 가 실행되는 클러스터의 인증 토큰값을 이용해야 하는데, Airflow 의 KPO Pod가 실행되는 클러스터 토큰 값을 이용하여 Spark가 실행되는 클러스터를 인증 시도를 하기 때문에 문제가 발생했다.
2-2) Solution
위의 이슈에 대해서 airflow, spark 각각 실행을 하나의 클러스터에서 진행하게 되면 문제는 해결할 수는 있다.
하지만, waitAppCompletion=false로 설정을 사용하되, k8s client 를 이용하여 상태를 polling 하는 방식으로 문제를 해결하였다.
waitAppCompletion=false 로 설정을 하되 k8s client 를 통해 직접 polling 했을 때의 장점은 아래와 같다.
첫번째로, 끊긴 연결에 의존하지 않아 안정적이다.
watch는 연결을 계속 유지하는 구조라 네트워크 순단, 세션 만료, 인증 갱신 등에 취약한 반면, polling은 매 주기마다 새로 요청을 보내 현재 상태를 조회하는 stateless 방식이라, 한 번의 요청이 실패해도 다음 주기에 다시 시도하면 되므로 일시적인 장애에 훨씬 강하다.
두번째로, 종료 판정 로직을 직접 제어할 수 있다.
드라이버 파드의 phase(Succeeded, Failed, Running 등)를 직접 보고 종료 조건을 정의할 수 있다.
폴링 주기, 타임아웃, 재시도 횟수, 실패시 예외처리 등을 상황에 맞게 커스터마이징할 수 있어, spark-submit의 watch 동작에 그대로 끌려가지 않는다.
이때 파드의 상태는 두 층위로 나눠서 보면 로직이 깔끔해진다.
파드 전체의 라이프사이클은 pod.status.phase 로 판단하고(Succeeded/ Failed 로 종료를 판정), 그 안의 개별 컨테이너 상태는 pod.status.containerstatuses로 확인한다.
각 컨테이너 state 는 running / terminated 등으로 표시되며, 실패 원인을 디버깅할 때는 여기서 exitCode와 함께 reason(예: Error, OOMKilled) 를 보면 된다.
즉, 종료 판정은 phase 기준으로, 실패 원인 분석은 containerStatuses 기준으로 역할을 나누는 것이다.
예를 들면, 30초마다 driver pod 의 상태를 폴링 해오고, 현재 pod 내에 있는 컨테이너의 status 등을 모니터링하면서 각 status가 어떻게 변화하는지 로깅으로 출력해줄 수 있다.
또한, 실패가 발생하면(phase == Failed) containerStatuses에서 exitCode 와 종료 reason을 확인하고, 파드에서 실패 로그를 가져와 Slack alert으로 전달하는 등의 후처리 로직도 자유롭게 구성할 수 있게 된다.
3. Ivy 패키지 다운로드 동작 방식 차이
3-1) Root Cause
기존 Spark on YARN 에서 잘 쓰던 Ivy 패키지 다운로드(–packages)가 Spark on K8s 로 옮기자 아래 에러를 내며 실패했다.
java.io.FileNotFoundException:
/opt/spark/.ivy2/cache/resolved-org.apache.spark-spark-submit-parent-<uuid>-1.0.xml
(No such file or directory)
근본 원인은 Spark on YARN 과 Spark on K8s 의 Ivy 동작 방식 차이에 있다.
Ivy는 여러 패키지를 한꺼번에 resolve할 때 이들을 묶는 가상 부모 모듈(spark-submit-parent-<uuid>)을 만들고, 그 resolve 결과(resolved-..-1.0.xml)를 캐시 디렉터리에 써야 한다.
그런데 driver pod 안에서 이 쓰기가 일어나야 하는데 이미지의 .ivy2 디렉터리가 없거나 쓰기 권한이 없어 위 에러가 발생한 것이다.
resolve/resolution 은 Ivy(또는 Maven 계열 도구)가 이 패키지를 쓰려면 실제로 어떤 jar 파일들이 필요한지 알아내고, 그것들을 다 갖춰놓은 전체 과정을 의미한다.
왜 driver pod 안에서 쓰기가 일어나는지를 이해하려면 YARN과 K8s의 동작 차이를 확인해야 한다.
공통 과정
--packages(= spark.jars.packages) 를 주면, Spark는 SparkSubmit 단계에서 Apache Ivy로 의존성을 resolve한다.
지정한 라이브러리를 Maven 에서 받아 로컬 Ivy 캐시에 저장한다.
<HOME>/.ivy2/cache 는 resolve 메타데이터이며,
<HOME>/.ivy2/jars 에는 실제 jar 파일이 들어간다.
받은 jar들의 경로를 spark.jars 에 자동 추가한다.
Ivy Default Cache set to: <HOME>/.ivy2/cache 한줄이 이 과정이다.
여기까지는 YARN이든 K8s든 동일한 과정이다.
다만, driver, executor가 이 목록의 jar를 실제로 어떻게 받아 클래스패스에 올리는지는 환경마다 다르다.
주요한 차이는 어디서 resolove하고, 어떻게 executor까지 전달하느냐에서 갈린다.
Spark on YARN
resolove가 spark-submit을 실행한 클라이언트(KPO Pod)에서 일어난다.
spark-submit을 실행하는 계정의 홈 디렉터리 ~/.ivy2 에 jar가 내려받아지고, 그 다음 YARN의 distributed cache가 이 jar 들을 HDFS 스테이징 디렉터리에 올린 뒤 각 컨테이너로 localize 해준다.
distributed cache는 YARN이 제공하는 파일 배포 메커니즘이며, 잡 실행에 필요한 파일을 클러스터의 여러 노드 컨테이너에 자동으로 복사해주는 기능이다.
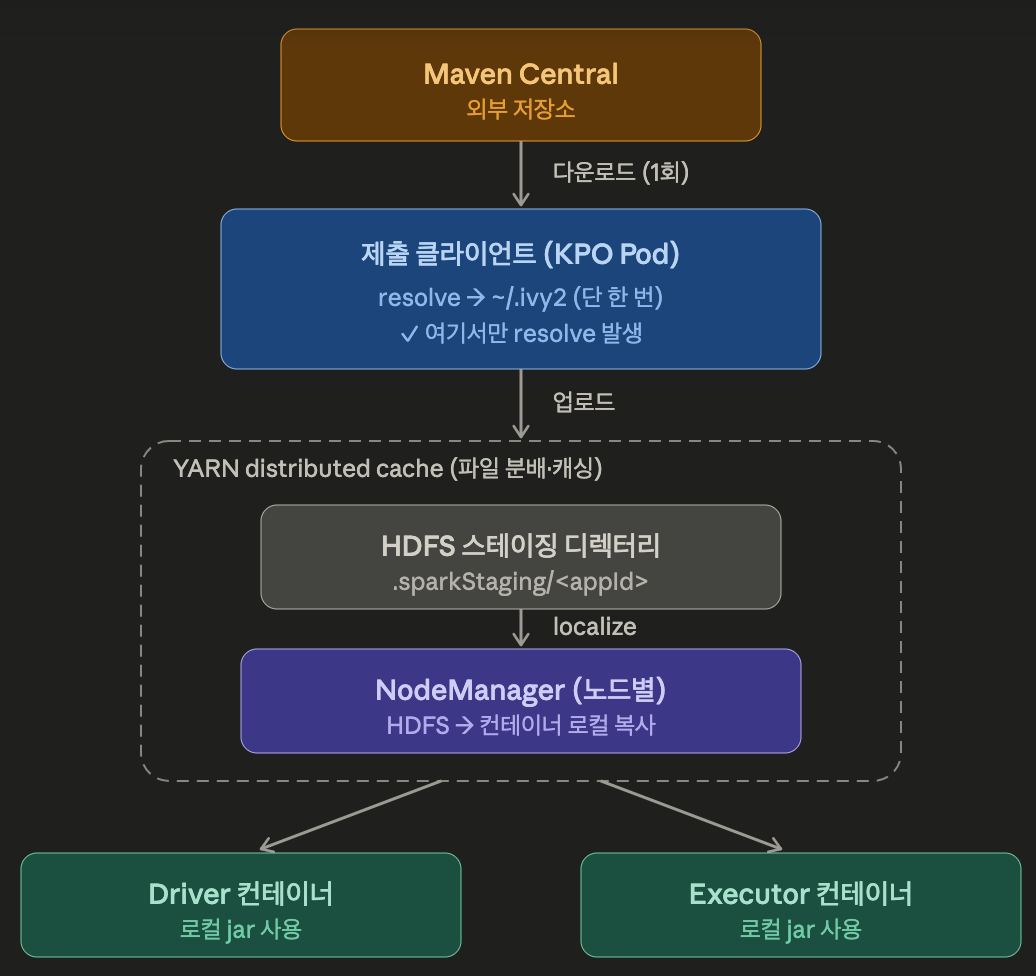
즉, jar를 노드들에 뿌려주는 기능이 플랫폼에 내장되어 있어서, --packages가 별도 설정 없이 동작하게 된다.
기존에 ivy 패키지를 어플리케이션 실행시마다 매번 다운로드를 해야하기 때문에, 제출 클라이언트(KPO Pod) 에 spark.jars.ivy 의 경로를 PVC 로 마운트 해두고, 그 한 곳의 캐시가 계속 재사용될 수 있도록 구성했었다.
spark.jars.ivy=/opt/ivy 와 같은 경로를 지정하고 해당 경로를 PVC 마운트를 해두었다. resolve는 매번 일어나도 다운로드는 캐시가 비어 있을 때만 발생하기 때문이다.
Spark on K8s.
K8s 에는 YARN distributed cache 영역이 없기 때문에 그 역할을 driver pod가 대신한다.
따라서, cluster 모드의 핵심 차이가 여기 있다.
Ivy resolve는 제출 클라이언트(KPO Pod) 와 driver pod 모두 발생한다.
KPO Pod 에서는 spark-submit cluster 모드를 –packages와 함께 실행하면, 가장 먼저 prepareSubmitEnvironment 단계를 거치게 된다.
이 단계에서 spark.jars.packages가 있으면 ivy resolve을 수행한다.
하지만 k8s 환경에서는 이렇게 resolve된 결과가 driver pod 안에서는 쓸모가 없다는 것이다.
실제 사용되는 패키지는 driver pod 내에서 다시 resolve하게 된다.
cluster 모드로 spark-submit 수행시 driver pod 스펙만 만들어서 K8s에 요청하고 종료하고, 띄워진 driver pod가 내부적으로 spark-submit을 client 모드로 다시 실행한다. 그렇기 때문에 제출 클라이언트(KPO Pod) 와 driver pod 가 각각 ivy resolve을 수행하는 이유이다.
이는 driver pod 이미지 엔트리 포인트에서 spark-submit –deploy-mode client 로 되어 있음을 확인할 수 있다.
그렇기 때문에, YARN 에서는 KPO Pod 내에 있는 디렉토리 경로 권한만 확인하면 되었지만, K8s의 경우 Driver Pod 내에 해당 경로의 권한이 필요했고, 해당 경로의 권한이 없어서 문제가 발생했다.
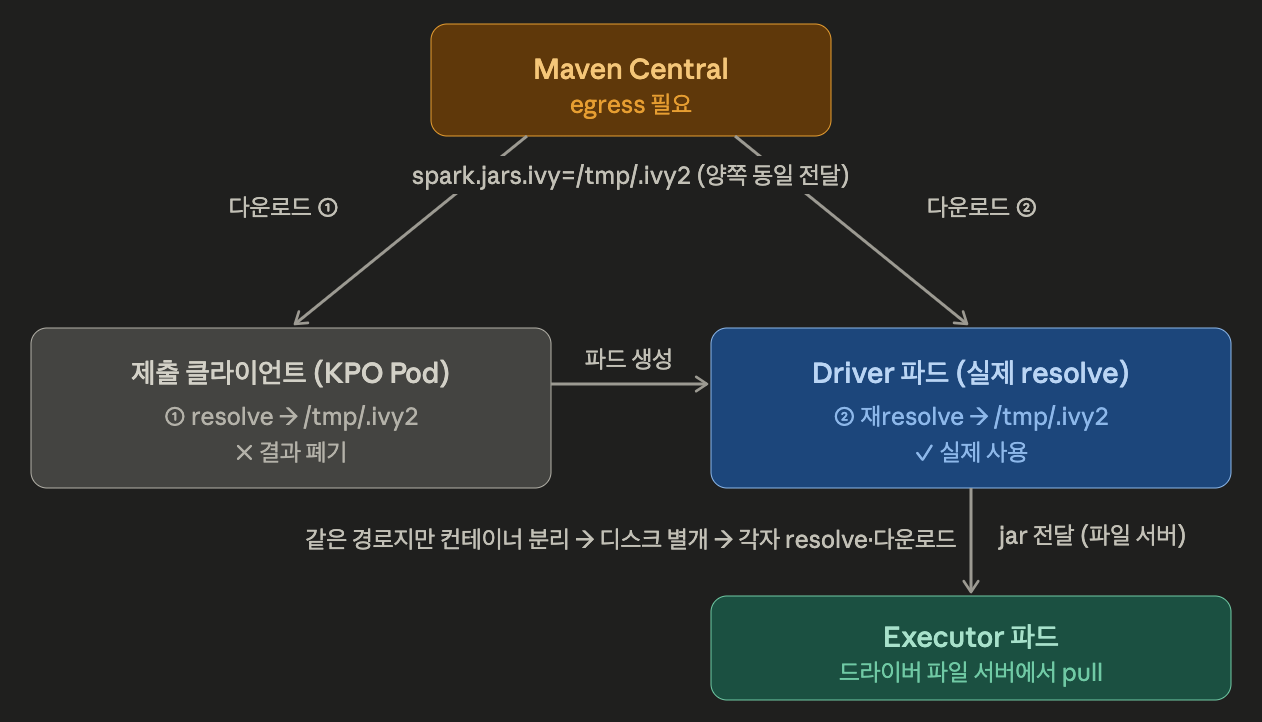
executor로의 전달도 다르다. distributed cache가 없으니, driver가 resolve해 가진 jar를 자신의 파일 서버로 노출하고, executor는 시작 시 드라이버 주소(SPARK_DRIVER_URL)로 접속해 jar를 받아 간다.
Solution
따라서, K8s 에서는 driver pod 관점에서 두 가지를 확인 및 보완해야 한다.
- ivy 캐시 쓰기 권한: spark.jars.ivy=/tmp/.ivy2 처럼 쓰기 가능한 경로를 지정하거나, 지정한 경로에 대해서 이미지내에 디렉터리 생싱 및 권한을 부여한다.
- Maven egress: driver pod가 Maven central(또는 사내 Nexus/Artifactory) 로 나갈 수 있는지 확인해야 한다.
다만 가장 견고한 방법은 런타임 resolve에 의존하지 않는것이다.
의존성을 이미지에 미리 빌드하여 넣어두거나, s3 등 외부 저장소에 두고 받아 쓰는 방식으로 가면 resolve, 다운로드 단계를 스킵하여 조금더 빠르게 어플리케이션을 실행할 수 있게 된다.
–conf spark.jars=s3a://my-bucket/jars/foo.jar,s3a://my-bucket/jars/bar.jar \
Reference
https://spark.apache.org/docs/latest/running-on-kubernetes.html
https://medium.com/@titieiti.com/airflow-kubernetesexecutor%EC%99%80-kubernetespodoperator-19d470e40a1e
https://github.com/fabric8io/kubernetes-client/blob/v6.4.1/kubernetes-client-api/src/main/java/io/fabric8/kubernetes/client/Config.java