현재 업무에서 Spark on YARN(Cloudera Data Platform) 환경에서 Spark Job을 제출하여 Spark 어플리케이션을 실행하고 있다.
이를 운영하면서 발생한 문제점은 아래와 같다.
전통적 Hadoop/YARN 클러스터에서 저장(HDFS DataNode)과 컴퓨팅(YARN NodeManager)이 같은 노드에 함께 배치된다.
이는 data locality를 노린 의도적 설계라 성능 향상에 도움이 되지만, 반대로 스케줄러가 data locality를 최대화하려고 데이터가 몰려 있는 소수 노드로 작업을 집중시키면서 그 노드에 부하가 쏠리는 문제가 발생한다.

YARN은 네트워크로 데이터를 옮기는 비용을 아끼려고, 가능하면 데이터가 있는 바로 그 노드에서 작업을 실행하려고 한다.
이를 위해 지금 빈 노드가 있어도, 데이터가 있는 노드가 곧 빌 것 같으면 잠깐 기다렸다가 그쪽에 배치하는 식으로 동작한다.
문제는 데이터가 모든 노드에 고르게 퍼져 있지 않다는 점이다.
예를 들어 여러 쿼리가 같은 테이블을 자주 읽으면, 그 테이블 블록을 가진 소수 노드로 작업 요청이 집중 된다.
그럼 스케줄러는 계속해서 그 데이터가 존재하는 노드에서 작업을 처리하도록 지시를 하게 되면 해당 노드는 과부하(핫스팟)가 되며, 데이터를 적게 가진 나머지 노드는 놀게 된다.
게다가 스케줄러가 핫스팟 노드가 빌 때까지 작업을 붙잡아 두기 때문에, 전체 job 완료 시간까지 늦어지게 된다.
그리고, 기본적으로 클러스터의 자원이 고정되어 있어서 활용률이 저하된다.
CDP on-premise 환경을 사용하고 있기 때문에 물리 노드가 고정되어 있어서 Auto Scaling이 불가능하다.
노드 증설을 할 때도, 만약 스토리지는 넉넉한데 컴퓨팅 자원이 부족할 경우도 함께 증설되어야 하므로 자원 활용면에서 비효율적이다.
또한, YARN 의 dedicated Queue 를 이용하여 특정 조직/팀 단위로 자원을 할당받아서 사용하고 있다.
즉, maximum-capacity를 고정하는 운영 정책이기 때문에 자원 낭비는 구조적으로 발생할 수 밖에 없다.
비용을 maximum-capacity 를 기준으로 지불해야 하기 때문에 피크타임이 아닌 시간에는 남는 리소스가 많이 발생하게 된다.
그 이전 회사에서는 CDP on-premise가 아닌 EMR 클러스터에서 Spark를 운영한 경험이 있고, EMR 클러스터에서는 Auto Scaling을 지원하지만 아래 문제가 있었기 때문에 K8s로 전환을 고려 했었다.
목적에 따라 여러 EMR 클러스터를 구성하거나 DR 을 대비하여 여러 EMR Cluster 를 구성해야 할 때가 있다. 즉, Multi AZ로 구성하여 운영해야 하는데 EMR Cluster 비용이 기본적으로 비싸기 때문에 많은 비용이 발생한다.
EMR Cluster는 하나의 AZ 에만 프로비저닝 할 수 있기 때문에, DR 을 대비하기 위해 다른 AZ에 동일한 EMR 클러스터를 구성하여 active-active cluster 를 구성하여 해결 할 수는 있지만 비용이 2배로 발생하게 된다.
하나의 AZ 에 문제가 발생하였을 때 다른 AZ 를 통해 job 을 실행하여 가용성을 확보할 수 있다.
그리고 또 하나의 문제점은 Spark 버전과 사용 라이브러리의 버전 유연성이 떨어진다.
EMR Cluster 자체가 특정 버전에 묶여 있기 때문에 클러스터 자체를 업데이트 하지 않는 이상 고정된 Spark 버전과 특정 라이브러리 버전을 사용해야 한다.
spark, iceberg, java, aws 등의 라이브러리를 고정된 버전을 사용해야 한다.
CDP on-premise 또한 버전이 고정되어 의존성 문제가 발생할 수 있다.
마지막으로 모니터링 관점에서 한계가 존재한다.
CDP on-premise 와 EMR은 플랫폼이 모니터링을 기본적으로 제공하지만 커스터마이징이 제한적이고, Spark 레벨의 메트릭을 모니터링하는데 어려움이 존재한다.
예를 들면 Spark Executor별 메모리 사용 패턴이나 Task 별 처리 시간 등
위의 문제점을 기반으로 하여 Spark on K8s 로 전환했을 때 이를 해결할 수 있는지 확인해보려고 한다.
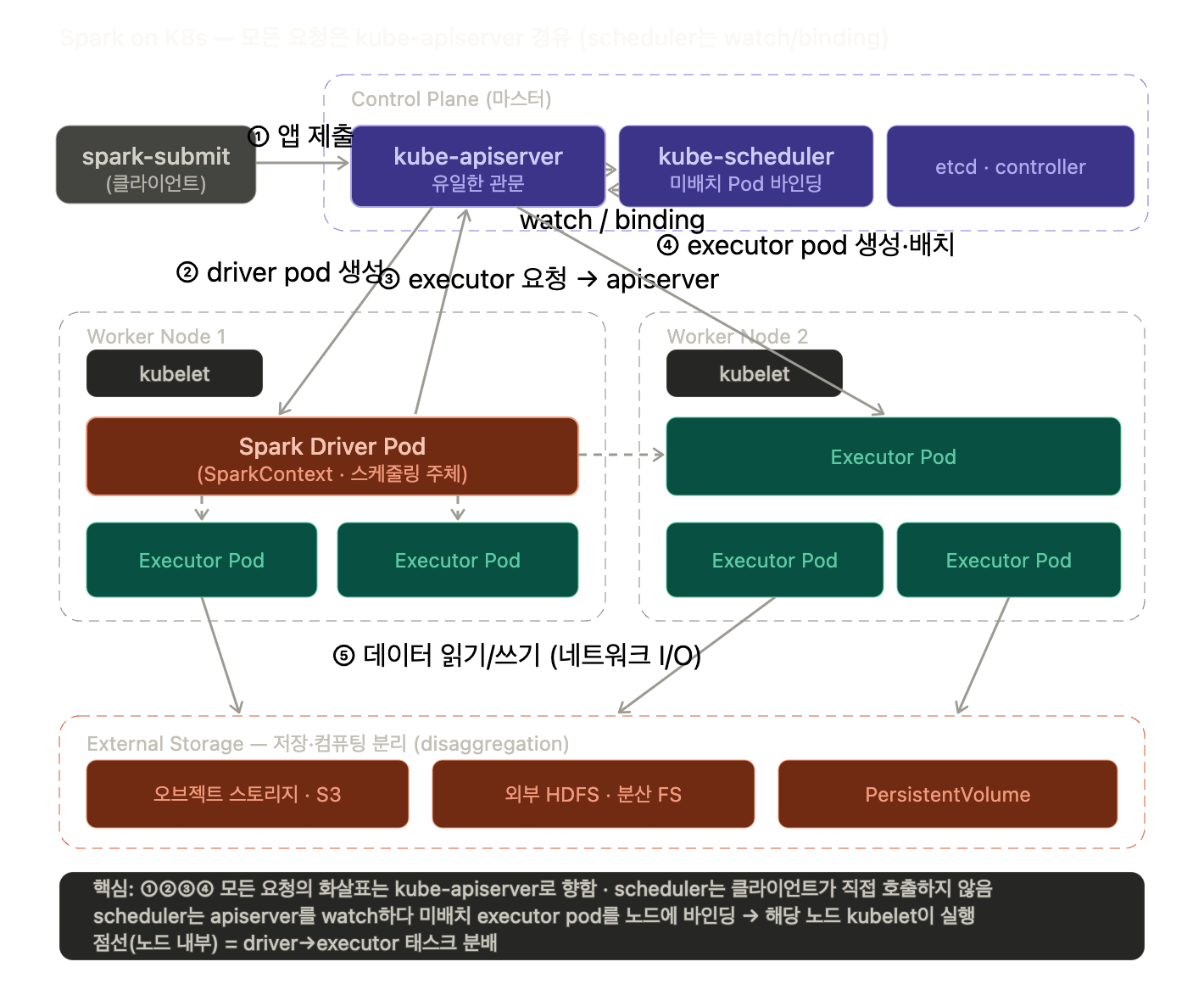
K8s 아키텍처의 기본 골격은 Control Plane(마스터)과 Worker Node로 나뉜다.
Control Plane 에는 모든 요청의 관문인 kube-apiserver, Pod를 어느 노드에 둘지 정하는 kube-scheduler, 클러스터 상태를 저장하는 etcd와 controller(kube-controller-manager)가 있다.
Worker Node에는 노드별 에이전트인 kubelet이 떠서 실제 Pod를 실행한다.
spark-submit을 하면 실행 흐름은 다음과 같이 이어진다.
요청이 먼저 kube-apiserver로 전달되어 Spark Driver Pod 생성이 등록된다.
이때 노드가 정해지지 않은 Pod를 kube-scheduler가 발견해 적절한 워커 노드에 배정하고, 해당 노드의 kubelet이 Driver Pod를 실행한다.
실행된 Driver Pod 안에서는 SparkContext가 생성되어, 잡을 작은 태스크 단위로 나누고 그 태스크를 executor들에 분배, 관리하는 역할을 한다.
Driver는 필요한 executor 수만큼 다시 kube-apiserver에 executor Pod 생성을 요청한다.
요청으로 등록된 미배치 executor Pod를 kube-scheduler가 각 워커 노드에 배정하면, 그 노드의 kubelet이 executor Pod를 띄운다.
그 후 executor들은 Driver가 분배한 태스크를 수행하며, 데이터를 외부 저장소(s3, hdfs, pv)에서 네트워크로 읽고 쓴다.
잡이 끝나면 executor Pod는 정리되고 Driver Pod만 완료 상태로 남게 된다.
1. PoC 검증 항목
먼저, PoC 를 진행하여 아래와 같은 내용을 확인해보면서 전환시 어떠한 이점이 있는지 살펴봤다.
1-1) 멀티 버전 Spark 이미지 동시 실행
동일한 K8s 클러스터 내에서 서로 다른 Spark 버전 및 라이브러리 버전의 Job이 동시에 실행 가능한지 확인한다.
기존에는 클러스터에 고정된 Spark, Hadoop 등의 라이브러리로 인하여 Spark 버전 업그레이드를 진행하려면 클러스터 부터 업그레이드를 진행해야 했다.
따라서, 서로 다른 Spark 버전의 어플리케이션들이 동일한 클러스터에서 버전 충돌 없이 독립적으로 실행이 가능한지 확인한다.
1-2) Prometheus + Grafana 모니터링 확인
CDP 에서 불가능했던 Spark 어플리케이션 레벨의 실시간 메트릭 수집 및 시각화가 가능한지 확인 한다.
Grafana를 통해 현재 실행중인 Spark 어플리케이션의 리소스 사용량의 패턴을 모니터링 가능한지 확인한다.
1-3) Remote Shuffle Service 안정성 확인
YARN은 NodeManager가 External Shuffle Service를 기본적으로 제공하지만, K8s는 기본적으로 제공하지 않는다.
Spark의 Shuffle 데이터는 기본적으로 Executor 로컬 디스크에 저장되기 때문에, Executor가 종료(Preemption, Scale-in, Incident) 되면 Shuffle 데이터가 함께 사라져 Job 이 실패한다.
이를 해결하기 위해 Apache Celeborn을 RSS로 도입하여 Shuffle 데이터를 외부 서비스에 보존할 수 있게 된다.
Executor 종료 시 Shuffle 데이터 유실 없이 Job이 정상 완료 되었는지 확인한다.
또한, YARN External Shuffle Service 대비 성능 및 안정성을 비교한다.
Celeborn 장애 상황에서의 확인을 위해서 Celeborn을 미적용 상태에서 동작을 확인해본다.
1-4) 메모리 오버헤드 관리 및 OOM Kill 확인
Spark 메모리 오버헤드는 executor JVM on-heap 메모리 외에 컨테이너에 요청하는 추가 off-heap 메모리이다.
Python 프로세스, Apache Parquet 등 서드 파티 라이브러리에서 사용하는 off-heap 영역을 위해 사용한다.
Spark 메모리 오버헤드는 전체 컨테이너 메모리에 포함되어 OOM 이 발생하는 것을 막는 역할을 한다.
기본 값은 executor 메모리의 10%이며 spark.executor.memoryOverheadFactor 설정으로 조절 할 수 있다.
참고로, spark.kubernetes.memoryOverheadFactor 는 Spark 3.3.0 부터 deprecated 되었다.
k8s 환경에서는 20% ~ 40% 범위를 기본값으로 사용하는 것이 권장된다.
그 이유는 Spark on k8s 환경에서는 spark on yarn 환경과 비교해서 같은 양을 써도 OOM 이 더 자주 발생하게 된다.
그 이유는 CDP, EMR 의 YARN은 기본적으로 NodeManager가 일정 주기로 컨테이너 메모리를 폴링해 체크하기 때문에, 순간적인 메모리 스파이크를 감지하지 못하고 넘어가는 경우가 있어서 상대적으로 느슨하게 동작한다.
반면, K8s 의 경우 할당된 메모리 한도를 cgroup이 실시간으로 감지하고 넘어서면 그 즉시 OOM Kill을 발생시킨다.
1-5) YARN dedicated queue 대비 자원 활용율
Spark on K8s 에서는 Apache YuniKorn 을 사용할 예정이며, YuniKorn 스케줄러의 계층형 Queue와 우선순위 정책을 활용하여 자원 격리와 효율적인 공유를 동시에 달성하는지 확인한다.
YuniKorn Queue의 guaranteed/max 설정과 preemption 정책으로 YARN Dedicated Queue 대비 전체 자원 활용률이 향상되는지 확인한다.
1-6) Karpenter Auto Scaling 및 Dynamic Resource Allocation 확인
워크로드에 따라 노드가 동적으로 확장/축소 되는지 확인한다.
CDP on-premise 는 물리 노드가 고정되어 있는 반면 K8s는 Auto Scaling이 가능하다.
또한, Spark on k8s에서 Dynamic Resource Allocation 동작을 Spark on YARN 과 비교한다.
1-7) Spark on YARN 대비 성능 비교
Spark on K8s의 Job 실행 성능이 기존 Spark on YARN 대비 허용 가능한 수준인지 확인한다.
동일한 Spark Job을 CDP 와 K8s 환경에서 실행하여 실행시간, 자원 사용량, Shuffle 성능을 비교한다.
Spark on YARN 과 Spark on K8s의 옵션 및 환경을 유사하게 구성하고, 동일한 어플리케이션을 실행 후 Spark History Server MCP를 이용하여 분석 및 비교 해보자.
PoC 검증 결과
Spark on YARN 의 환경
- Spark Version: 3.4.1
- Java 1.8
- Shuffle Service: External Shuffle Service(ESS)
- GC: Parallel GC(Default)
K8s
- Spark Version: 3.4.4
- Java 11
- Shuffle Service: Remote Shuffle Service(RSS) / Celeborn
- GC: G1GC
Spark on K8s 의 경우 3.4 부터 ESS 없이도 Dynamic Allocation 이 안정적으로 작동 가능해졌으며, 3.4.4 에서 마이너 버그들이 대부분 해결되었기 때문에 해당 버전을 사용했다.
위와 같은 환경 차이 외에 spark.executor.memory=20GB, cores=4 그리고 spark.dynamicAllocation.maxExecutors=200으로 동일하게 구성하여 성능 테스트를 진행했다.
Reference
https://blog.banksalad.com/tech/spark-on-kubernetes/
https://justkode.kr/data-engineering/spark-on-k8s-1/
https://techblog.woowahan.com/10291/
https://spot.io/blog/setting-up-managing-monitoring-spark-on-kubernetes/
https://aws.amazon.com/ko/blogs/containers/optimizing-spark-performance-on-kubernetes/
https://techblog.lycorp.co.jp/ko/processing-large-scale-data-with-spark-on-kubernetes