1. Airflow Architecture
1-1) Scheduler
DAG 정의를 주기적으로 읽고, 실행해야 할 DAG Run과 Task Instance를 판단해
Metadata DB에 기록한다.
Dag 파일 처리 주기 관련 설정은 아래와 같다.
- scheduler_heartbeat_sec
- scheduler가 DB에 heartbeat 신호를 남기고 태스크 스케줄링 루프를 도는 주기
즉, 스케줄러는 지속적으로 실행되는 서비스로, 프로덕션 환경에서는 항상 작동 중이어야 한다.
Airflow 2.x 부터는 여러 Scheduler 프로세스를 동시에 실행 가능한 Multiple Scheduler를 지원한다.
따라서 이전에는 하나의 scheduler에 부하가 걸리거나 장애가 발생하면 DAG 스케줄링이 지연되거나 멈출수 있기 때문에
여러 Scheduler 프로세스를 실행하여 성능 향상을 할 수 있다.
그럼 어떻게 Multiple Scheduler는 Metadata DB 에 동시에 접근을 제어할까?
Airflow는 행 단위 락(Row-level lock)을 사용하여 critical section을 제어한다.
즉, 같은 Task Instance를 동시에 잡지 않도록 DB 락을 활용한다.
단, 주의해야할 점은 Scheduler 수가 많아질수록 메타데이터 DB 쿼리도 늘어나므로, DB 성능이 중요하며 너무 많은 Scheduler 갯수 설정은 오히려 성능 저하가 발생할 수 있다.
PostgreSQL 12+ 또는 MySQL 8.0+ 을 이용하여 동시성 제어를 지원하는 버전을 권장한다.
아래는 scheduler 갯수를 2로 설정한 예이다.
scheduler:
replicas: 2
1-2) DAG Processor
Scheduler의 서브 컴포넌트로서, DAG 파일을 파싱해 DAG 객체로 변환한다.
파싱된 DAG는 Metadata DB에 직렬화되어 Webserver나 Scheduler에서 불필요한
재파싱을 방지한다.
1-3) Webserver
사용자에게 UI를 제공하는 컴포넌트로, DAG 상태, 태스크 로그, 실행 기록 등을
조회할 수 있다.
Flask 기반이며, Gunicorn을 통해 다수의 웹 서버 프로세스를 띄운다.
1-4) Worker
Task Instance를 실제로 실행하는 프로세스이다.
Executor에 따라 Celery, Kubernetes, Local 등의 방식으로 분산 실행이 가능하며,
각 태스크의 상태와 로그는 Metadata DB에 기록된다.
1-5) Triggerer
Triggerer 프로세스는 비동기 이벤트 기반 태스크를 처리하는 전용 컴포넌트이다.
AsyncSensor, TriggerDagRunOperator 등에서 사용되며, 리소스를 효율적으로 사용해
수천 개의 태스크도 오버헤드 없이 관리할 수 있다.
TriggerDagRunOperator는 일반적으로는 Worker에서 실행되지만, deferrable=True 옵션을 주게되면 Triggerer 프로세스에서 이벤트 기반으로 실행될 수 있다.
1-6) DAG Files
Python 스크립트 형태로 DAG 정의가 작성된 파일들이다.
1-7) Metadata DB
Airflow의 모든 상태 정보(TaskInstance, DagRun, Log 등)를 저장하는 핵심 데이터베이스이다.
Scheduler, Webserver, Worker가 이 DB를 중심으로 상태를 주고 받으며 동기화한다.
1-8) Plugins folder
사용자 정의 Operator, Hook, Sensor, Macros 등을 등록할 수 있는 확장 경로이다.
Airflow는 이 디렉토리의 파일들을 로드하여 사용자 정의 기능을 플러그인처럼 활용할 수 있다.
2. Airflow2 vs Airflow3 비교
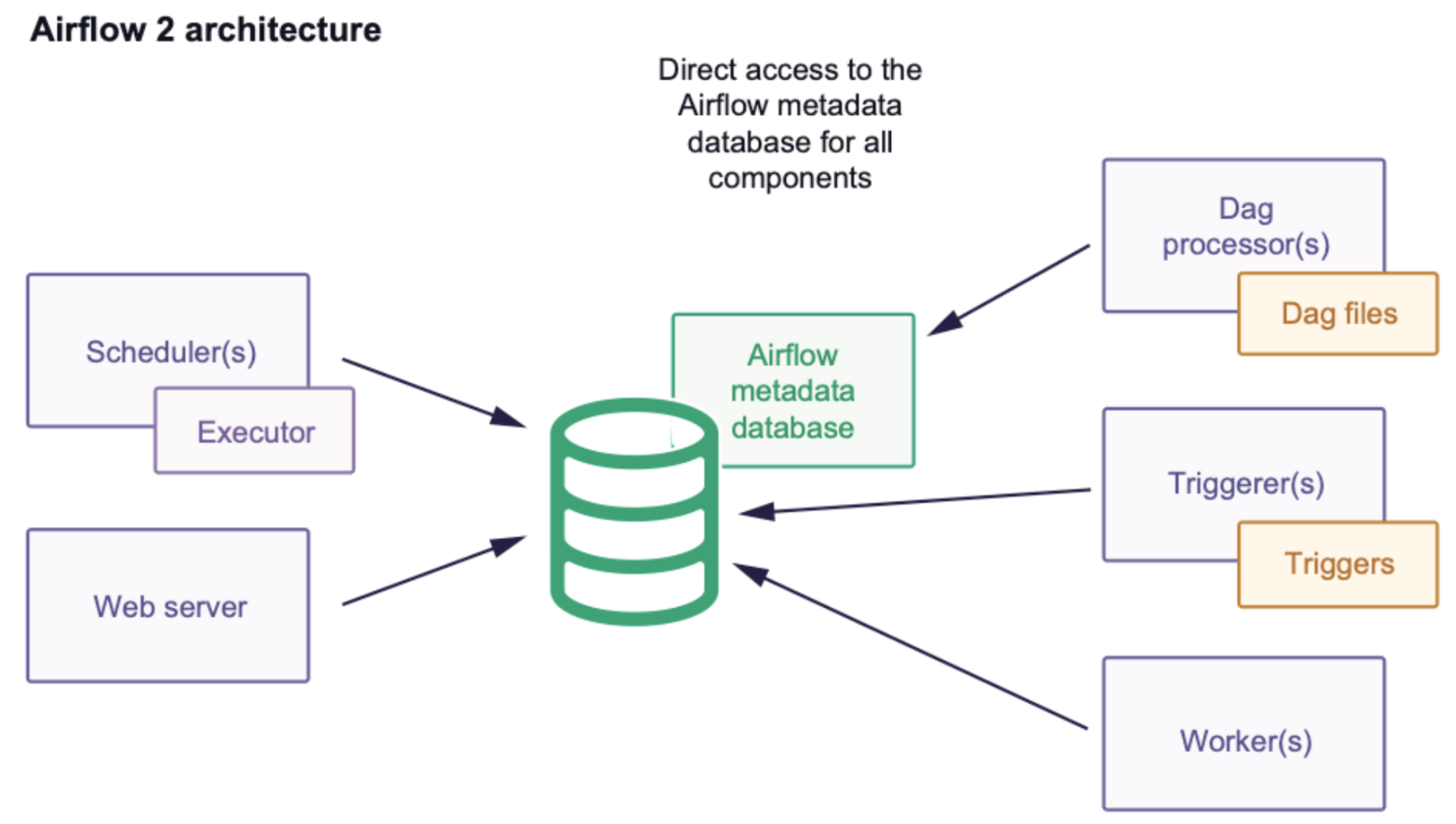
Airflow2 에서는 모든 component 는 Metadata DB 와 직접적으로 통신하였다.
특히 Worker가 직접 Metadata DB 와 통신하면서 많은 connection 갯수가 필요하며, scaling 에 대한 고려가 필요할 수 있다.
또한, Worker가 직접 Metadata DB를 바라보고 있으니, 사용자 코드가 데이터베이스에 악의적인 작업을 수행할 수도 있게 된다.
Airflow3 로 업그레이드 되면서 security, scalability, maintainability 를 향상시키기 위한 많은 변화가 있다.
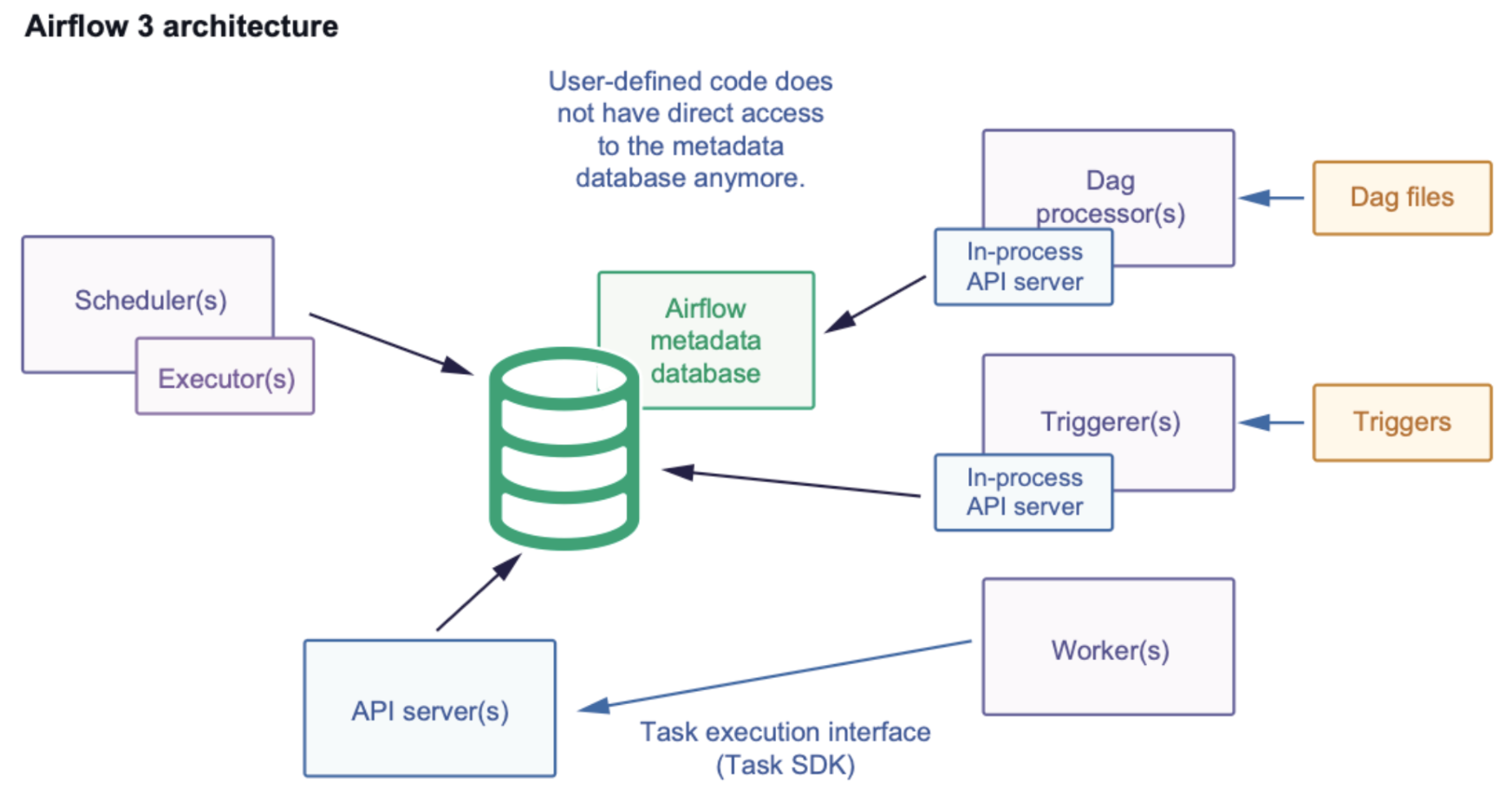
Airflow2 에서 Web Server가 Airlfow3에선 API Server로 명칭이 변경되었다.
Airflow2 Worker에서 직접 Metadata DB를 접근하였으나, Airflow 3에선 API Server를 경유하여
DB를 접근하게 변경되었다.
Airflow2에선 DAG Author에 의해 작성된 코드가 DB에 직접적으로 영향을 줄 수 있기 때문에 이를 방지하려는 목적이다.
이러한 변경은 악의적인 task code가 Metadata DB를 변경하거나 접근하는 것을 막음으로서 보안을 향상시킬 수 있게 된다.
3. DAG Serialization
기존에는 Webserver와 Scheduler가 둘다 DAG 파일을 직접 파싱을 했었고, 아래 문제가 발생했다.
- 두 컴포넌트 모두 DAG 파일이 있는 공유 스토리지 접근이 필요하다.
- Webserver 재시작, 스케일 아웃 시 파싱 비용과 의존성이 커진다.
- 서로 다른 환경에서 파싱해 UI와 실제 스케줄링 불일치가 발생할 수 있었다.
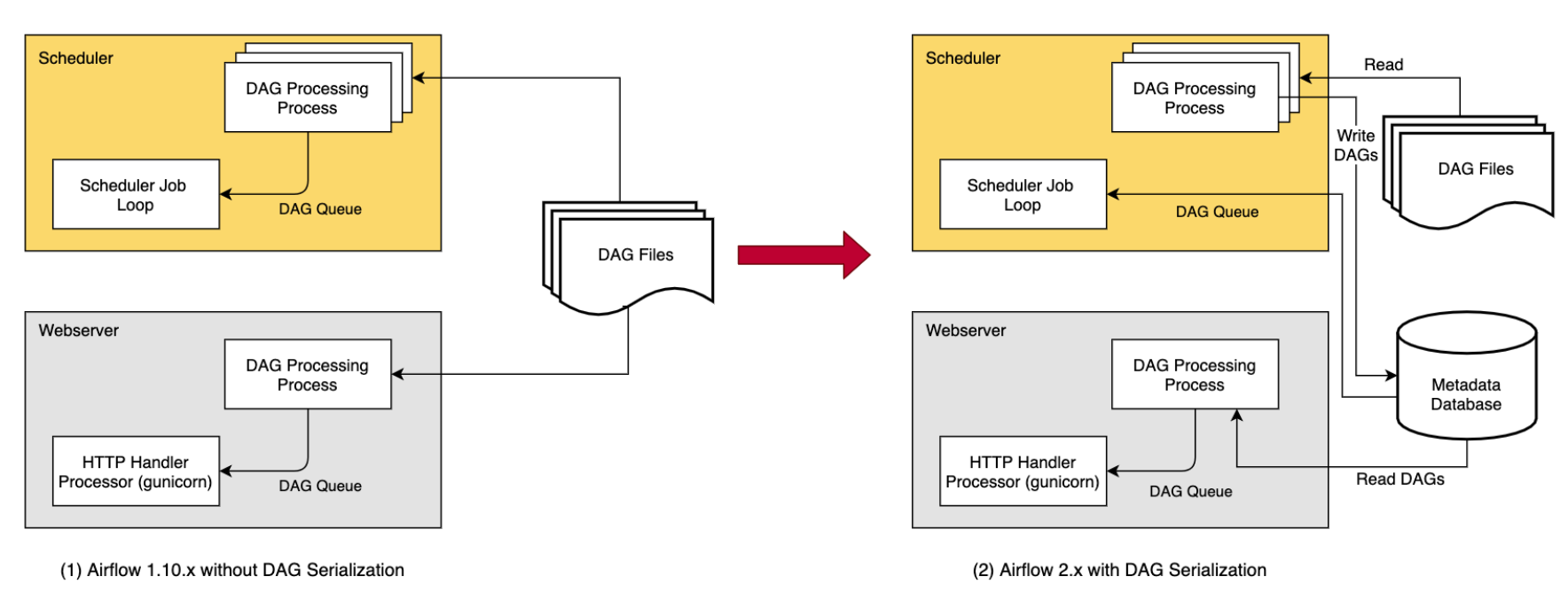
Airflow 1.10.7 부터 DAG 를 json 직렬화해 Metadata DB에 저장하고, Webserver는 DB만 읽는 구조가되어 stateless에 가까워졌고, Airflow 2.0 부터는 Scheduler도 이 직렬화된 DAG 으로 스케줄링을 결정하게 되었다.
Airflow 2.x 부터는 직렬화는 필수이며, 비활성화는 불가능하다.
DAG 파일 파싱은 DagFileProcessorProcess가 수행하며, 결과는 JSON 포맷으로 직렬화를 하고 최종적으로 SerializedDagModel 로서 Metadata DB에 저장된다.
Webserver는 DAG 파일을 직접 파싱하지 않고, DB에서 직렬화된 DAG를 읽어 UI를 구성한다.
이렇게 하는 이유는 경량화가 가능하기 때문이다.
Webserver는 모든 DAG를 한 번에 로딩하지 않고 요청 시 개별 DAG를 로드한다.
Reference
https://medium.com/29cm/29cm-apache-airflow-%EC%9A%B4%EC%98%81%EA%B8%B0-da6b5535f7a6