최근에 5년 가까이 일했던 쿠팡에서의 업무를 마무리를 했고, 진행했던 주요 프로젝트 및 회고를 해보자.
1. CS data pipeline
1-1) Problem Statement
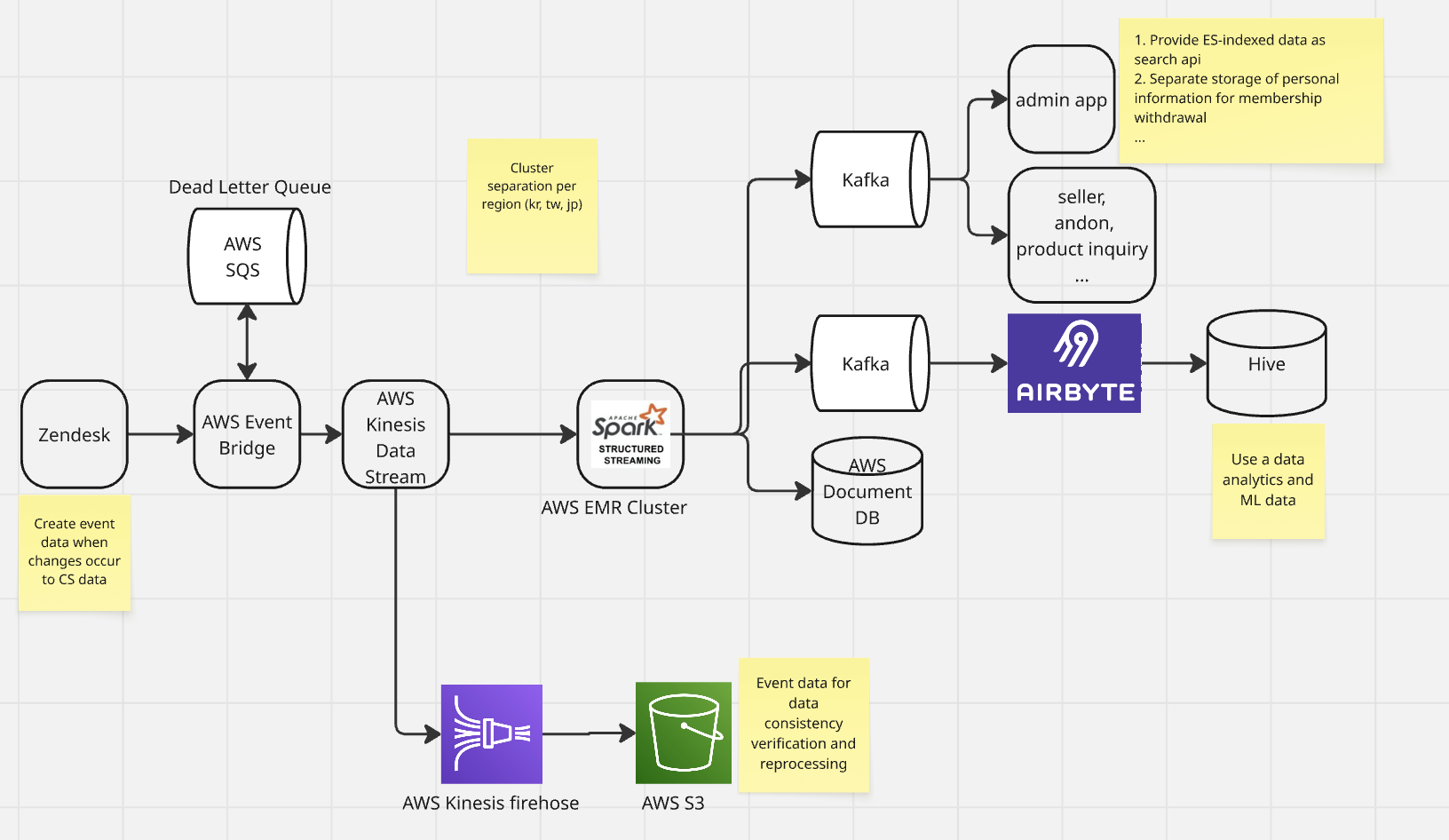
- Spark streaming에서의 processing delay 발생
- 복잡한 비지니스로 인하여 많은 DB I/O
- RDD 기반이기 때문에 Catalyst Optimizer, Tunsten project, AQE 를 통한 성능 향상이 어려움
- 동시성 이슈 및 데이터 순서 보장이 되지 않는 이슈
- 재처리 프로세스 및 checkpoint 관리에 대한 이슈
- 데이터 정합성 확인이 어려운 구조
Auto Detecting 이 아닌 Manual Detecting 으로 데이터 정합성 확인이 가능
1-1) Tech Challenge
- RDD 기반의 Spark Streaming을 Dataframe 기반의 Spark Structured Streaming으로 전환
- 스트리밍에서 발생하는 DB I/O 최소화
- OLTP 용도로 사용이 필요한 데이터만 DocumentDB 에 저장하며, 그 외에 데이터는 Airbyte 를 이용하여 동기화하도록 전환
- Repartition을 통한 동시성 이슈 해결
- Checkpoint를 hdfs에서 s3로 전환
- EMR Cluster의 hdfs 를 checkpoint로 사용할 경우 cluster 장애 발생 및 다른 az zone에 클러스터 생성하여 복구시 checkpoint loss 발생
- Kinesis firehose를 도입하여 이벤트 단위의 원본데이터 저장
- processing 된 데이터와 주기적으로 비교하여 데이터 정합성 확인
- 해당 데이터를 이용하여 필요시 데이터 백필 진행
2. Pyspark Environment
기존에는 airflow 에서 제공하는 SparkSQLOperator 를 이용하여 Spark를 사용했었고, 여기서 확인된 문제는 아래와 같다.
2-1) Problem Statement
- 여러 단계의 변환, 조인이 발생하는 복잡한 쿼리에 대해서는 유지보수가 어려움
- 모듈화가 어려워서 로직 재사용이 어려움
- 컴파일 단계에서 타입, 컬럼 오류 확인이 어려움
- Spark 의 cache를 활용하여 성능 최적화가 어려움
- Mysql 과 같이 다른 데이터베이스와의 조인 등을 통해 연산을 하지 못함
2-2) Tech Challenge
- Dataframe 기반으로 코드 작성할 수 있는 Pyspark 환경을 구성하여 복잡한 비지니스에 대해서 코드를 효율적을 관리하도록 구성
- Airflow 코드와 비지니스 로직을 분리하여 코드 복잡성 감소 및 테스트가 용이한 환경으로 구성
- Airflow DAG 내에서 직접 비지니스 로직을 호출하면 테스트할 때 항상 Airflow Context에 의존해야 함
- 분리하게 되면 Airflow 외에 Pyspark 에서 실행되는 비지니스 로직만 검증이 가능
- Trino 커넥션을 이용하여 기본적인 로컬 테스트가 가능하도록 구성
- CircleCI 를 통해 각 github 브랜치 별로 독립적으로 실행가능하도록 패키징하여 운영환경에 영향 없이 QA 가능한 구조로 구성
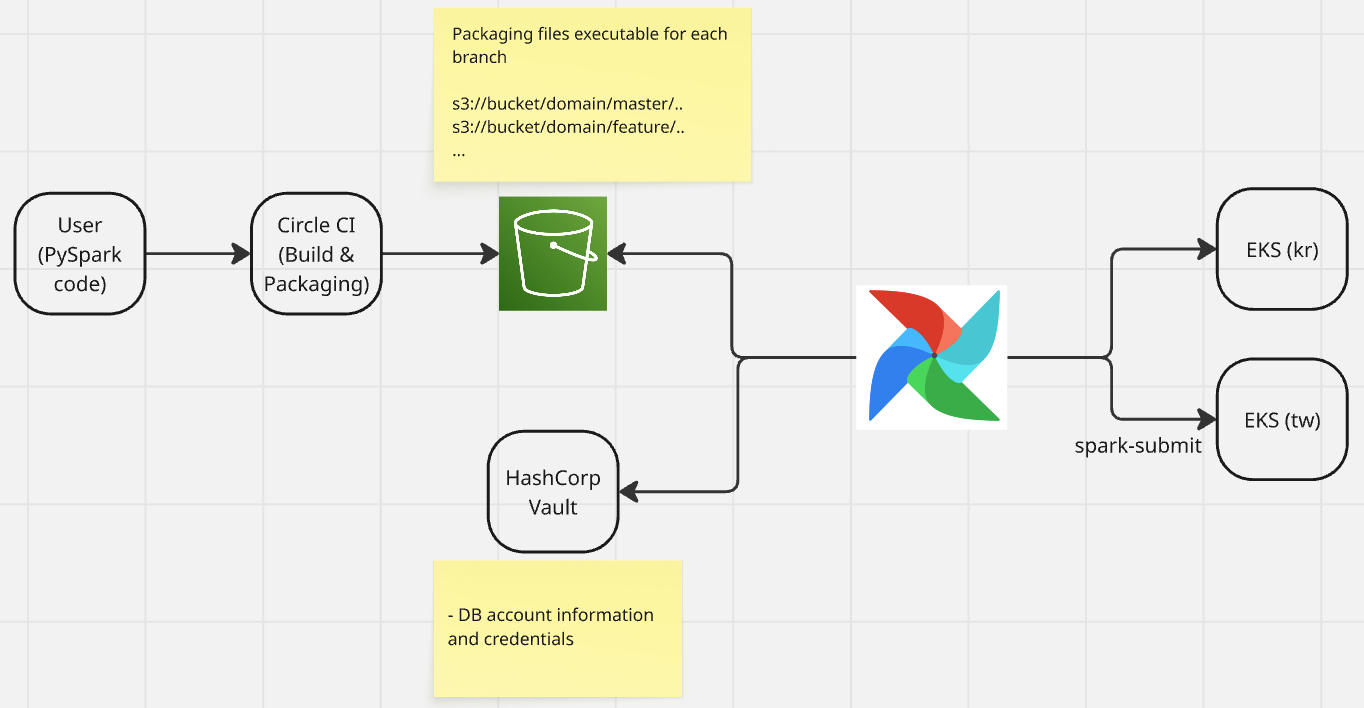
Python Package Management 를 참고하여 환경 구성 하였다.
3. Migrate from hive to iceberg
3-1) Problem Statement
- ACID 트랜잭션을 완벽하게 지원하지 않는 문제
- 스키마 확장성 미지원
- hive 는 컬럼 이름 기반으로 스키마를 관리하는 반면 iceberg는 각 컬럼럼에 고유한 id를 부여하여 스키마를 관리하기 때문에 유연하고 안전한 스키마 변경이 가능
- 과거 데이터에 대한 Tracking이 어려움
3-2) Tech Challenge
- ACID 트랜잭션을 지원
- Schema Evolution 제공
- Time Travel & Rollback 을 제공하기 때문에 과거 히스토리 조회 가능
- Expire snapshot, Orphan file 을 Daily로 정리해주는 배치를 통해 관리할 수 있도록 하며, 스트리밍처럼 small file이 발생하는 경우도 Compaction을 하도록 관리
Reference