현재 업무에서 Iceberg 테이블을 사용하여 여러 데이터를 동기화하고 있고, 특정 버전에서 이슈가 확인되어 이를 자세히 살펴볼 예정이다.
이를 잘 이해하기 위해 iceberg에서 manifest 의 개념과 역할에 대해서 먼저 살펴보자.
1. Manifest list 이해
Manifest list의 역할은 특정 스냅샷과 연관된 data files(manifests) 들을 트래킹하기
위한 목록이다.
간단하게 스냅샷에 어떤 데이터 파일들이 포함되어 있는지 정리한 목록이다.
manifest list의 주요 목적은 아래와 같다.
1-1) The Role of Manifest list
Efficient Data Tracking
데이터를 직접 하나하나 스캔하지 않고, 어떤 데이터가 어디에 있는지를
효율적으로 트래킹할 수 있도록 한다.
Atomic Snapshot Management
스냅샷이 생성될 때마다 manifest list가 생성되고,
manifest list는 어떤 데이터들이 포함되어 있는지 정보를
한번에 가지고 있기 때문에 변경된 사항에 대해 atomic 하게
업데이트가 가능해진다.
Optimization of Query Execution
쿼리를 실행하게 되면 iceberg는 전체 데이터를 스캔할 필요가 없다.
manifest list와 manifest 파일을 먼저 확인하여
관련된 데이터만 골라서 읽을 수 있다.
1-2) Key Components of the Manifest list
manifest list 안에 포함되어 있는 주요 필드에 대해서 살펴보자.
{
"manifest-list": [
{
"manifest_path": "s3://bucket/path/to/manifest1.avro", # manifest file 위치
"manifest_length": 1048576,
"partition_spec_id": 1, # iceberg는 테이블의 파티션 전략(spec)이 진화할 수 있기 때문에 각 manifest 마다 어떤 파티션 스펙을 기반으로 만들어졌는지 이 필드로 구분한다.
"content": 0, # 데이터 파일은 0, 삭제 파일은 1로 표기
"sequence_number": 1001, # 이 manifest가 언제 테이블에 추가되었는지를 나타내는 버전 정보(이를 기반으로 time travel 가능)
"min_sequence_number": 1000, # 이 manifest가 추적하는 가장 오래된 데이터 파일의 버전
"added_files_count": 5,
"existing_files_count": 10,
"deleted_files_count": 2, # 이러한 정보들을 가지고 있기 때문에 쿼리시 skip 할 대상들을 빠르게 판단할 수 있다.
"added_rows_count": 500000,
"existing_rows_count": 1000000,
"deleted_rows_count": 200000,
"partitions": [
{
"contains_null": false,
"contains_nan": false,
"lower_bound": "2023-01-01", # 쿼리 조건이 있다면 이 요약 정보를 보고 manifest를 읽을지 말지 미리 판단 가능 (partition pruning)
"upper_bound": "2023-01-31"
}
]
},
{
"manifest_path": "s3://bucket/path/to/manifest2.avro",
"manifest_length": 2097152,
"partition_spec_id": 2,
"content": 0,
"sequence_number": 1002,
"min_sequence_number": 1001,
"added_files_count": 8,
"existing_files_count": 7,
"deleted_files_count": 3,
"added_rows_count": 750000,
"existing_rows_count": 700000,
"deleted_rows_count": 150000,
"partitions": [
{
"contains_null": true,
"contains_nan": false,
"lower_bound": "2023-02-01",
"upper_bound": "2023-02-28"
}
]
}
]
}
위에서 중요한 필드 중 하나는 sequence_number 필드이며, 어떤 데이터가 언제 추가 또는 삭제되었는지 버전 번호를
부여 하기 때문에 time travel을 할 때 이 정보를 참조한다.
또한, content, partition_spec_id, lower_bound, upper_bound 등에 대한 정보를 저장하기 때문에 쿼리시
불필요한 파티션이나 데이터를 pruning 할 수 있게 된다.
마지막으로 added_files_count, existing_file_count, deleted_files_count 필드를 이용하여 I/O 성능을 향상할 수 있다.
삭제된 파일만 있는 manifest 는 무시할 수 있기 때문에 읽을 파일을 최소화 할 수 있다.
2. Manifest file 이해
manifest file은 실제 데이터 파일들을 트래킹하며, 파일위치, 파티션 정보, 통계 정보(record count, size 등) 를 담고 있다.
2-1) The Role of Manifest Files
manifest file의 사용목적은 아래와 같다.
Tracking Data Files
manifest file의 가장 기본적인 역할은 어떤 데이터 파일들이 이 스냅샷에 포함되었는지를 트래킹하는 것이다.
- file_path: 데이터 파일의 저장 경로
- file_format: 데이터 파일 형식(e.g. Parquet, ORC)
- partition_data: 이 파일이 어떤 파티션에 속하는지
- record_count: 이 파일에 몇 개의 레코드가 있는지
- file_size_in_bytes: 이 파일의 크기
- column_statistics: 각 컬럼의 min/max, null 개수 등
Facilitating Efficient Scans
manifest file은 쿼리 성능을 최적화하는데 중요한 역할을 하며, 아래 정보들을 기반으로 데이터 파일을 미리 걸러내는 pruning이 가능해진다.
- lower_bounds, upper_bounds: 컬럼별 최소/최대값
- value_counts, null_value_counts, nan_value_counts: 각 컬럼에 대해 어떤 값이 얼마나 들어있는지 확인
- split_offsets: row group(parquet) / stripe(orc) 단위로 데이터를 나누는 지점이며, 분산처리가 가능해진다.
2-2) Manifest File과 Manifest List의 관계
하나의 manifest list는 여러 manifest file 들을 가지고 있고, 하나의 manifest file은 여러 데이터 파일을 가지고 있다.
즉, 계층 구조로 관리함으로써 많은 데이터를 효율적으로 관리할 수 있게 된다.
query optimization 관점에서 쿼리가 실행되면 manifest list에서 manifest file 들을 pruning을 진행하여 필요한 manifest file만 읽어들이고 manifest file에서는 데이터 파일들을 pruning 하여 필요한 데이터 파일만 읽을 수 있는 구조가 된다.
3. Iceberg 1.4.0 issue
Spark 배치를 통해서 데이터를 Iceberg 테이블에 동기화 하는 과정에서 아래와 같은 에러 발생하면서 배치가 실패하였다.
java.lang.IllegalArgumentException: requirement failed: length (-6235972) cannot be smaller than -1
버전 정보는 아래와 같다.
- Iceberg 1.4.0
- Spark 3.4.1
- EMR Cluster 6.15.0
확인해보니, Iceberg 1.4.0 을 사용할 경우 발생할 수 있는 known issue로 확인했다.
결과적으로 1.4.1 버전부터 해당 이슈가 fix 되었고, 버전 업그레이드 후
데이터 파일을 rewrite 하면서 문제는 해결되었다.
CALL spark_catalog.system_rewrite_data_files(table => 'db.table', options => map('target-file-size-bytes', '251658240', 'delete-file-threshold', '0'))
그럼 이러한 이슈가 왜 발생했고, 어떻게 수정되었는지 살펴보자.
#8834를 자세히 살펴보면 manifest 로부터
split offsets을 읽는 과정에서 발생한 버그로 확인했다.
#8336 에서 BaseFile 객체의 split offsets을 캐싱하도록 변경하였는데, Avro 리더가 BaseFile 인스턴스를 재사용하면서 첫 번째 오프셋이 모든 파일에 재사용되면서 문제가 발생할 수 있음을 확인했다.
Snapshot (manifest list, e.g. snap-123.avro)
│
├── Manifest File 1 (manifest-abc.avro)
│ ├── DataFile 1 (data-001.parquet)
│ ├── DataFile 2 (data-002.parquet)
│
├── Manifest File 2 (manifest-def.avro)
│ ├── DataFile 3 (data-003.parquet)
│ └── DataFile 4 (data-004.parquet)
여기서 Avro 리더는 manifest 를 의미하며 data file 의 정보를 기록하고 있다.
또한, BaseFile은 iceberg에서 DataFile, DeleteFile 등을 나타내는 인터페이스이다.
즉, file path, file format, partition 정보, splitOffsets, record count, size 등의
정보를 가지고 있다.
select * from "db"."table$files";
-- 아래 정보들을 확인할 수 있다.
-- upper_bounds, lower_bounds
-- split_offsets
-- file_path
-- partition
-- record_count
-- file_size_in_bytes
이 이슈를 정리해보면 아래와 같다.
- Avro 파일(manifest)을 읽는 과정에서 BaseFile 객체가 재사용되었다.
- splitOffsets 정보가 있는 여러 파일이 순차적으로 매니페스트에 기록된다.
- 첫번째 파일의 splitOffsets 값이 그대로 다른 파일에도 복사되어 문제가 발생한다.
File path: s3://bucket/data/file1.parquet → SplitOffsets: [100, 300, 500]
File path: s3://bucket/data/file2.parquet → SplitOffsets: [100, 300, 500] # 잘못된 splitOffsets
File path: s3://bucket/data/file3.parquet → SplitOffsets: [100, 300, 500] # 잘못된 splitOffsets
여기서 핵심은 하나의 manifest file 안에 여러 data file 들이 있을 때만 발생하며,
하나의 manifest file 안에 하나의 data file 만 존재할 경우는
이슈가 발생하지 않는다.
그럼 이를 어떻게 수정하여 해결하였는지 살펴보자.
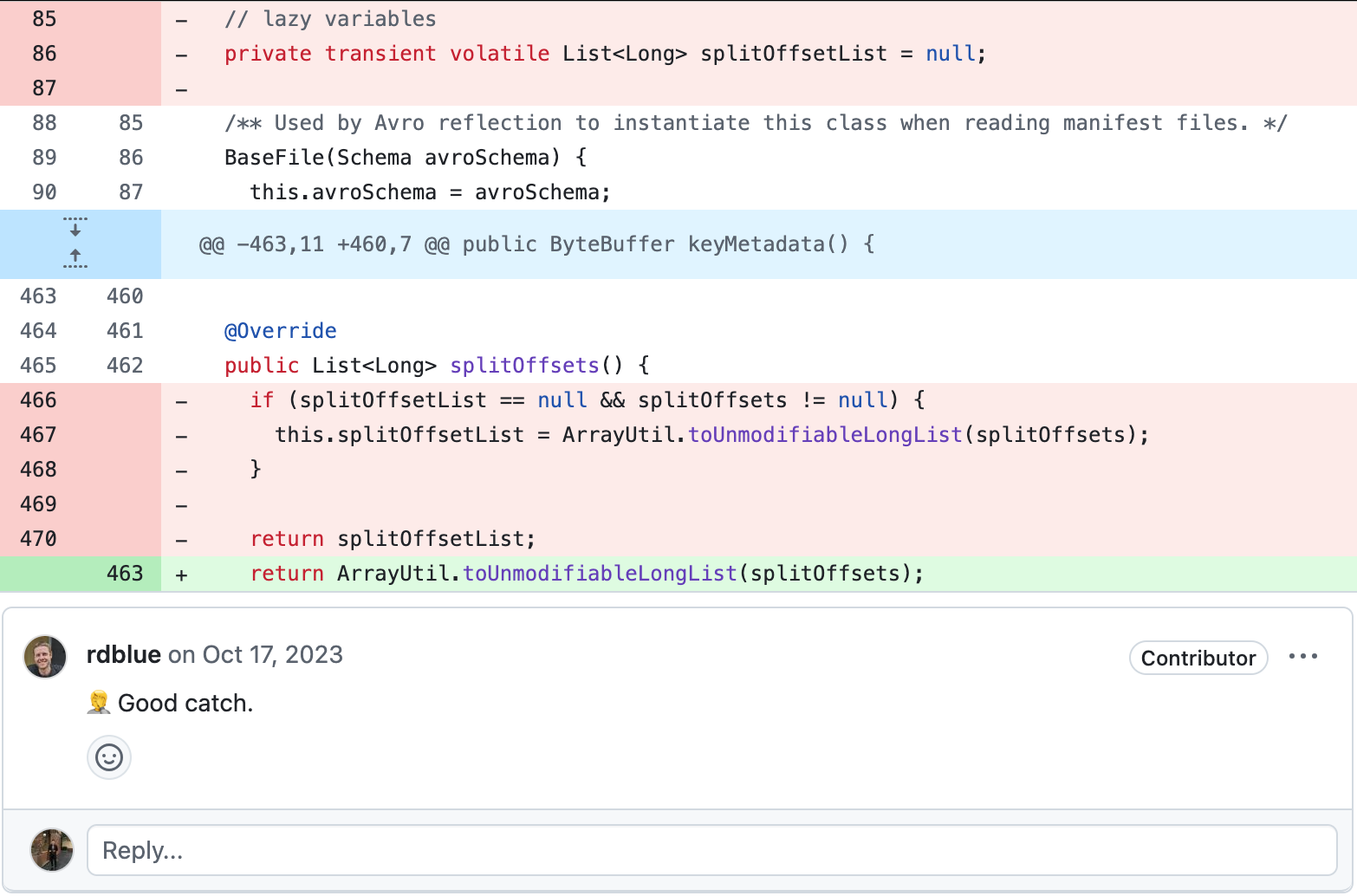
기존 구현에서 Avro 리더가 하나의 BaseFile 인스턴스를 재사용하는 구조였지만
이를 재사용하지 않도록 새로운 인스턴스를 매번 생성하도록 수정되었다.
4. Iceberg 에서 splitOffsets
splitOffsets는 iceberg의 data file 내에 split(데이터 블록)의 물리적인 위치(offset)정보를 담고 있다.
즉, iceberg에서 splitOffsets는 하나의 데이터 파일 내에 분할 가능한 지점(offset) 의 정보이다.
예를 들어 Parquet 파일 하나가 3개의 row group(=split)으로 구성돼 있다면 아래와 같다.
row group은 보통 128MB이며, 이를 넘을 경우 여러 row group으로 나뉘게 된다.
splitOffsets = [0, 1048576, 2097152] // 각 row group의 시작 위치
이는 Query Planning 시 pruning 이나 parallel read에 활용된다.
즉, 파일을 split 단위로 분산 처리할 수 있도록 도와준다.
https://github.com/apache/iceberg/pull/8834
https://github.com/apache/iceberg/issues/8863
https://github.com/apache/iceberg/issues/9689
https://dev.to/alexmercedcoder/understanding-the-apache-iceberg-manifest-file-581d
https://dev.to/alexmercedcoder/understanding-the-apache-iceberg-manifest-list-snapshot-507