전 세계적으로 데이터 생산량이 기하급수적으로 늘어나고 있다.
자연스레 기업은 방대한 데이터를 어떻게 효과적으로 수집하고
관리하고 활용해야 할지 고민하게 되었다.
이러한 고민 사이에 나타난 개념이 데이터 웨어하우스와 데이터 레이크이다.
전통적인 데이터 관리 방식인 데이터 웨어하우스와 최근 부상한
개념의 데이터 레이크는 데이터를 바라보는 관점과 활용 방식에
차이가 있다.
추가적으로 데이터 레이크하우스가 등장하게 되는데, 데이터 레이크와
데이터 웨어하우스의 장점을 결합한 것이다.
이번 글에서는 데이터 웨어하우스와 데이터 레이크의 차이점과 데이터 레이크하우스에 대해서 자세히 살펴볼 예정이다.
1. Data Warehouse vs Data Lake
데이터 웨어하우스와 데이터레이크는 모두 데이터 저장소의 형태지만
구조나 활용사례에서 그 차이가 있다.
1-1) Data Warehouse
데이터 웨어하우스는 기업이 다양한 데이터 소스에서 추출한 데이터를 통합하고, 정제하여 의사결정에 사용할 수 있는 형태로 변환하는 중앙 집중화된 데이터 저장소이다.
데이터 웨어하우스는 미리 결정된 목적을 위해 비지니스 어플리케이션에서 수집 및 생성하는 데이터 저장소이며, 저장 전 데이터에 미리 정의된 스키마를 적용하기 때문에 정형화된 데이터만을 다룬다.
따라서, 데이터가 저장되기 전 ETL(Extract, Transform, Load) 과정을 통해 정형화 되기 때문에 데이터가 일관성 있는 상태로 유지된다.
비즈니스의 의사결정을 돕기 위해 사용되는 데이터 웨어하우스는 여러 데이터베이스에 있는 데이터를 통합한 정형 데이터 분석 시스템으로 오랫동안 기업의 BI(Business Intelligence) 프로세스에서 핵심적인 부분을 담당했다.
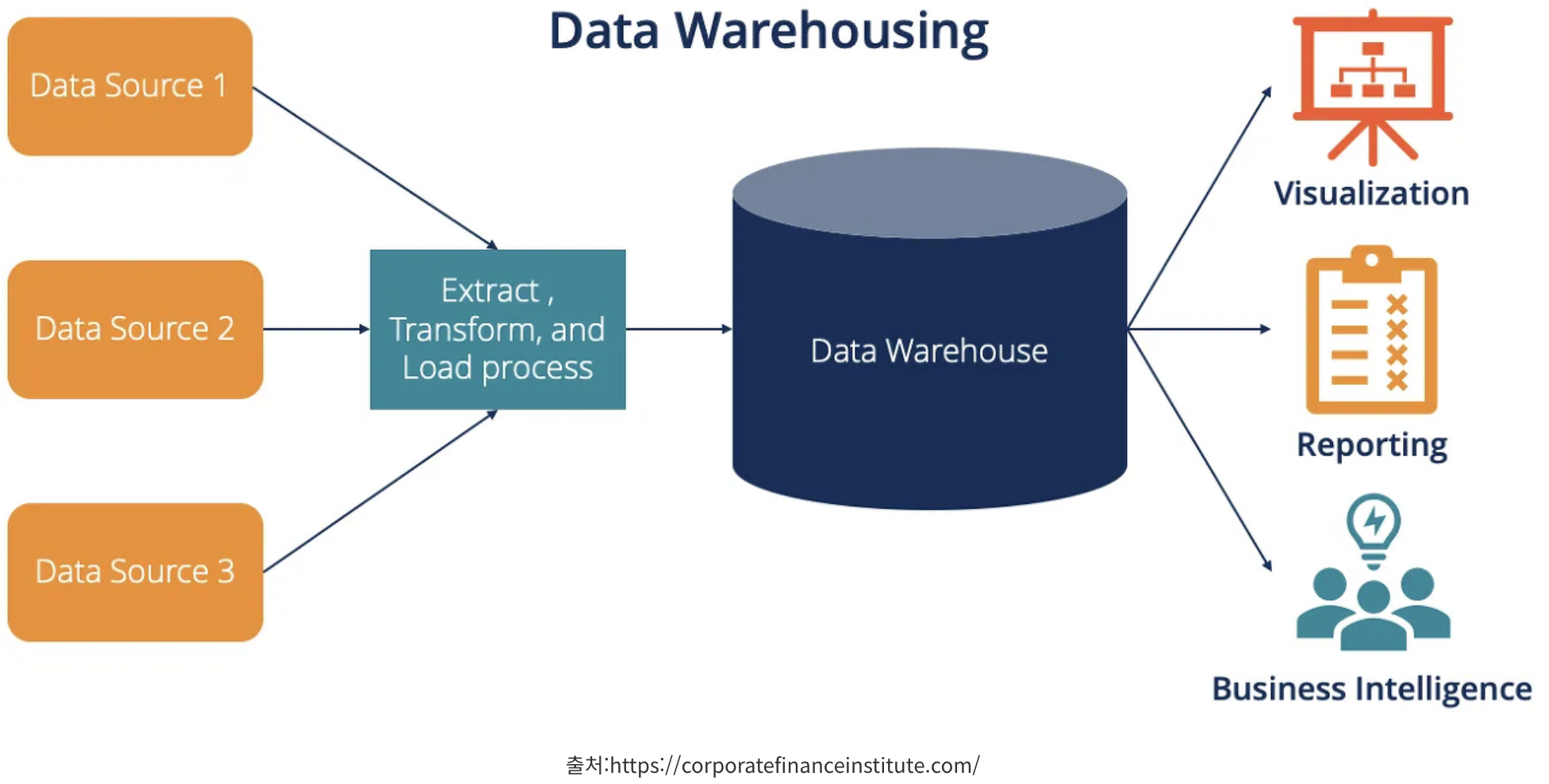
데이터 웨어하우스를 구성할 때 주로 Amazon Redshift, Google BigQuery, Snowflake 가 널리 사용 된다.
참고로, 데이터 마트(Data Mart)라는 단어는 데이터 웨어하우스의 하위 개념이다.
데이터 마트는 데이터 웨어하우스보다 작은 소규모 데이터 저장소를 의미한다.
특정 부서나 사업 부문의 의사결정을 지원하여 부서 단위의
요구사항에 맞춰 데이터를 추출, 정제, 통합하기 때문에 맞춤형 데이터 셋을 구축할 수 있다는
것이 장점이다.
그러나 2000년대 후반에 들어서면서 데이터 웨어하우스로는 대응할 수 없는 문제들이 나타나기 시작했다.
가장 큰 문제는 기업의 데이터의 양과 종류가 기하급수적으로 증가하고 있다는 점이다.
또한 기업의 데이터가 모두 유용한 가치를 가지고 있는 것이 아니었다.
데이터 웨어하우스는 데이터 사용에는 장점이 있지만 데이터 저장에 많은 공수가 들어간다.
또한, 데이터 웨어하우스의 경우 실시간으로 생성되는 데이터들을 활용하기 어렵고, 정형 데이터에 최적화돼있어서 최신 트렌드인 머신러닝이 요구하는 비정형 데이터 처리에는 적합하지 않다.
즉, 데이터 웨어하우스 방식인 ETL 의 장점은 데이터 저장하기 전 정형화된 데이터를 각 비지니스에 맞춰 스키마를 정의하여
데이터를 저장하기 때문에 downstream 에서 쿼리를 할 때 검증된 데이터를 조회할 수 있다는 장점이 있다.
고객의 민감한 정보나 금융 거래 데이터를 다룰 때 데이터가 정제되어야 할 비지니스 규칙이 명확하며, 모든 데이터가 일관된 상태로 유지되어야 하는 경우 ETL이 적합하다.
하지만, 저장하기 까지 데이터 클렌징 및 스키마 정의 등에서 많은 공수가 들며 비지니스 및 유즈케이스가 변경되면
다시 처음부터 작업을 진행해야 하기 때문에 공수 및 유지보수 비용이 많이 든다는 단점이 있다.
이를 해결할 수 있는 방안으로 떠오른 것이 바로 데이터 레이크이며, 데이터 레이크에 대해서 자세히 살펴보자.
1-2) Data Lake
데이터 레이크는 정형 데이터뿐만 아니라 반정형, 비정형 데이터와 같은 모든 유형의 데이터를 통합 및 저장하는 저장소이다.
오디오, 비디오 및 텍스트와 같은 다양한 유형의 데이터를 보관 가능하며, 구조화되지 않은 데이터를 생성하기 때문에 더 많은 데이터 과학 및 인공지능 프로젝트를 가능하게 하여 조직 전체에서 더 많은 참신한 통찰력과 더 나은 의사 결정을 이끌어 내므로 이는 중요한 차이이다.
데이터 레이크의 목적은 발생하는 모든 데이터들을 한 곳에 일단 저장하는 것이 목적이며, 일반적으로
S3, HDFS 같은 빅 데이터 플랫폼에 구축된다.
데이터 웨어하우스의 경우 데이터를 저장할 때 특정 스키마를 정의하지만 데이터 레이크는 데이터를 저장할 때 스키마를 정의하지 않고 우선 모아두었다가 필요한 데이터를 가져올 때 스키마를 정의한다
그렇기 때문에 저장하는 과정에서 별다른 처리를 하지 않기 때문에 빠르게 증가하는 데이터들을 신속하게 저장할 수 있으며, 필요한 경우 분석 시점에서 데이터를 변환하여 사용할 수 있는 ELT(Extract, Load, Transform) 방식을 주로 사용한다.
즉, 데이터를 읽어야 할 때 스키마를 적용한다. 예를 들어 HDFS에서 사용자는 데이터용 외부 하이브 테이블을 정의할 수 있다. 테이블에 쿼리가 발생하면 하이브는 파일의 데이터를 특정 테이블에 매핑해서 스키마에 맞춘다. 데이터가 스키마에 맞지 않으면 쿼리는 실패한다. 하지만 관계형 데이터베이스와는 달리 데이터는 여전히 HDFS에 저장돼 있어 보존된다. 적절한 스키마를 적용하기 전까진 사용할 수 없을 뿐이다.
데이터 레이크 활용 사례는 아래와 같다.
- 다양한 소스의 원본 데이터 통합 저장
- 실험적이고 탐색적인 데이터 분석 수행
- 머신러닝/딥러닝 모델 개발을 위한 데이터셋 구축
특정 예를 살펴보면, 물류 기업을 예시로 들어보자.
물류 기업에서는 드론과 부착된 센서를 통해 방대한 물류 데이터를 저장하고 있다.
이렇게 수집한 방대한 비정형 물류 데이터는 데이터 레이크 전략을 선택하여 수집, 관리될 수 있다.
반면, 데이터 레이크도 명확하게 단점이 존재하며 폭발적으로 늘어나는 데이터들을 빠르게 수집하는데에 유리하지만, 원천 데이터를 그대로 저장하다 보니 이를 활용하는 데에는 문제가 있을 수 밖에 없다.
보안에 취약하며, ACID 트랜잭션을 지원하지 않고 데이터 품질을 보장할 수 없다는 것이 큰 단점이다
일부 데이터에는 개인정보 보호 및 규제가 필요하지만 데이터 레이크는 관리 감독 없이 저장하게 된다.
2. 데이터 인프라의 진화와 레이크하우스의 등장
과거 데이터 인프라의 변화 과정을 간단히 정리하면 다음과 같다.
데이터 웨어하우스 -> 데이터 레이크 -> 레이크하우스
- 데이터 웨어하우스(DW): 정형 데이터를 저장하고 분석하는데 최적화되어 있다.
- 데이터 레이크(DL): 구조화되지 않는 대량의 데이터를 저장할 수 있는 유연한 환경을 제공한다.
- 데이터 레이크하우스(DLH): 데이터 웨어하우스의 분석 성능과 데이터 레이크의 확장성을 결합하였다.
대부분의 기업들은 데이터 웨어하우스와 데이터 레이크를 이용해 데이터를
관리해왔지만, 서로 반대되는 장점과 단점을 보유한 두 가지 기술들을
유지하면서 관리가 복잡해지고 비용이 증가하는 문제를 겪고 있다.
대다수 기업들은 목적에 맞게 구축한 데이터 웨어하우스와 모든 데이터를 날 것 그대로 모아두는 데이터 레이크라는 두 가지 체계를 동시에 운영하기에는 복잡하고 관리가 어려운 문제가 있었다.
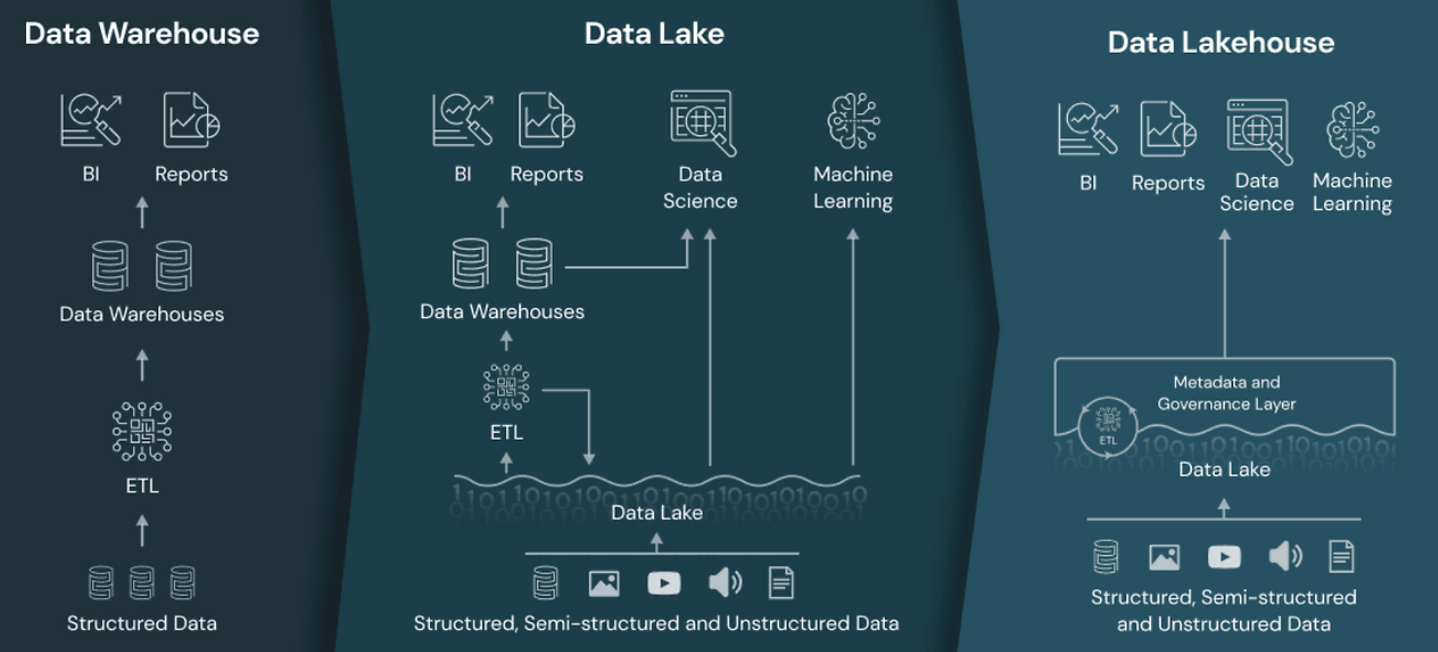
따라서 데이터 웨어하우스와 데이터 레이크의 장점을 결합한 데이터 레이크하우스가 새롭게 부각되고 있다.
레이크하우스는 데이터 레이크처럼 모든 유형의 데이터를 저장하면서도,
데이터 웨어하우스 수준의 성능과 관리 기능을 제공하는 것이 핵심이다.
3. 오픈 테이블 포맷(OTF)과 레이크하우스의 핵심 기술
레이크하우스를 가능하게 하는 중요한 기술 중 하나는 오픈 테이블 포맷이다.
대표적으로는 Delta Lake, Iceberg, Hudi 등이 있으며,
레이크하우스의 핵심 요소를 구성한다.
기존에 데이터 레이크에 파일 수준으로 저장되던 비정형 데이터들을 오픈 테이블 포맷을 이용해 논리적 테이블 수준으로 변환해 관리할 수 있다.
오픈 테이블 포맷의 주요 기능은 아래와 같다.
- ACID 트랜잭션 지원: 데이터 정합성과 안정성을 유지
- 배치 및 스트리밍 처리: 대량 데이터 처리를 빠르게 수행
- 유연한 스키마 및 파티션 관리: 데이터 구조를 쉽게 변경 가능
- 타임 트래블 지원: 이전 데이터 상태로 쉽게 복원 가능
Reference
https://www.biviz.ai/blog/read/?id=179
http://www.itdaily.kr/news/articleView.html?idxno=208876
https://www.cloocus.com/press_data-lakehouse-combines-dw-and-dl-advantages/