이번 글에서는 데이터 레이크 아키텍처로 주로 사용되는 람다 아키텍처와 카파 아키텍처에 대해서 살펴볼 예정이다.
실시간 수집이 필요한 경우 참조할 수 있는 아키텍처는 대표적으로 람다 아키텍처와 카파 아키텍처를 주로 사용한다.
1. Lambda Architecture
람다 아키텍처는 2011년 제시된 아키텍처로 실시간 수집이 필요한 경우 배치 처리와 스트림 처리를 모두 이용할 수 있는 아키텍처이다.
데이터 레이크에 대한 개념이 2010년에 등장했으며, 1년만에 람다 아키텍처가 등장했다는 것은 기존 구조에 문제가 있었기 때문에 등장 하였다.
기존 데이터 레이크의 문제점은 배치 Layer로 주로 구성이 되어 있었기 때문에 실시간 데이터를 다루기에 어려움이 존재했다.
따라서 배치로 수행하는 영역(배치 Layer)은 그대로 두고 실시간으로 수집하는 영역(스피드 Layer)을 추가하여, 배치 Layer와 스피드 Layer를 합쳐서 데이터 확인을 하는 것이 기본 컨셉이다.
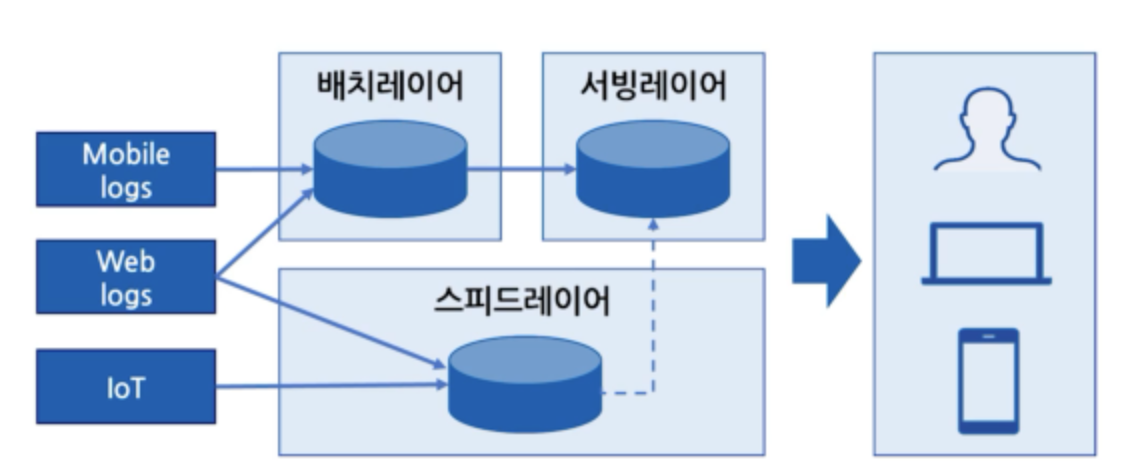
배치 Layer 를 HDFS 로 구성을 한다면, 서빙 Layer 는 Hive 로 사용하는 것을 예로 들 수 있다.
서빙 Layer 는 배치 Layer에 저장된 데이터를 빠르게 보여주기 위한 서비스 계층으로 사용자가 쿼리할 수 있도록 하며 필요에 따라 스피드 Layer 에 있는 데이터를 결합하기도 한다.
배치 Layer에 저장된 데이터가 D-1 기준 데이터라고 예를 들어보면 스피드 Layer 에는 당일 데이터가 저장, 정제하여 저장하는 공간이 될 것이다.
즉, 배치 Layer 에는 D-1 데이터가 저장되며, 그 이후에 발생한 데이터에 대해서는 스피드 Layer에 저장된다.
최종적으로 서빙 Layer는 배치 Layer와 스피드 Layer를 union 하여 쿼리를 진행하게 된다.
2. Kappa Architecture
카파 아키텍처는 2014년에 처음 등장하였으며, 람다 아키텍처에서 배치 뷰를 제거한 아키텍처이다.
기존 람다 아키텍처의 단점은 배치 Layer, 스피드 Layer 의 각 파이프라인을 유지해야 하기 때문에 관리와 복잡도가 증가 한다는 단점이 존재했다.
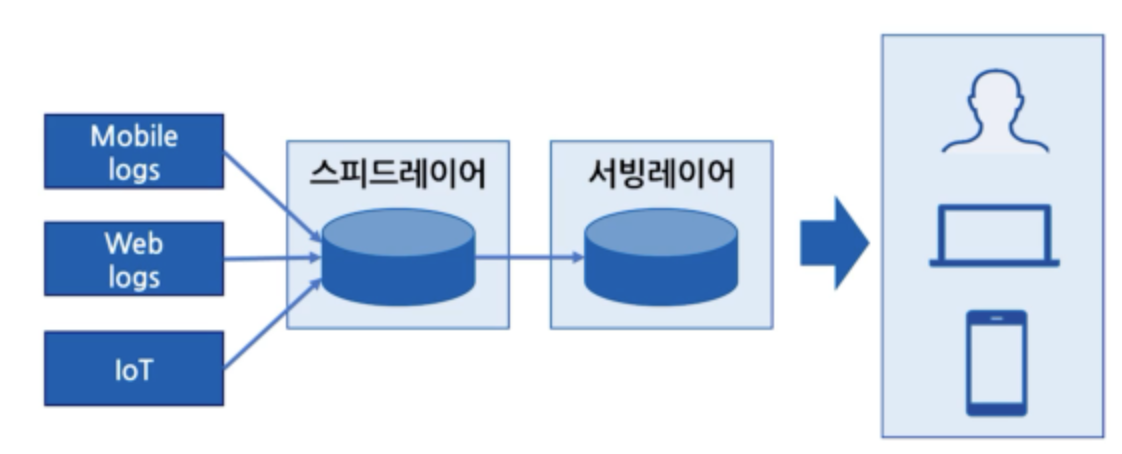
카파 아키텍처에서의 데이터 소스는 메시지 큐를 의미하며, 메시지 큐에는 여러 솔루션이 존재하지만 주로 Kafka를 사용하여 구성한다.
즉 카파 아키텍처에서 모든 데이터는 Kafka 로 수집함을 의미 하지만 데이터레이크 구성시 모든 소스를 Kafka 만으로 수집하는 경우는 많지 않다.
람다, 카파 아키텍처는 참조 아키텍처일 뿐 실제 구현되는 아키텍처는 필요한 파이프라인에 의해 다양하게 구성하는 것이 권장된다.
Reference
https://maru-itdeveloper.tistory.com/26