이번글에서는 Spark on K8s 에서 기본 스케줄러 대신 Apache YuniKorn 스케줄러를 사용하기 위해 관련 개념과 동작 방식 등을 자세히 살펴보자.
1. Apache YuniKorn
기본 kube-scheduler는 본질적으로 서비스 중심 스케줄러라 배치 워크로드에 아래와 같은 한계가 존재한다.
- 워크로드 큐잉이 없어 자원 부족 시 워크로드를 그냥 거부하기 때문에 재시도 로직이 필요
- 모든 워크로드가 클러스터 전체라는 동일한 자원 풀을 공유
- 어플리케이션 개념이 없어 어플리케이션 단위 스케줄링이 불가
- gang scheduling 개념이 없음
- 계층형 큐, 멀티테넌시, 큐별 쿼터 부재
Apache YuniKorn은 기본 K8s 스케줄러를 대체하면서도 계층형 큐, 큐 간 리소스 공정성, 작업 순서 지정(FIFO/FAIR), 노드 정렬 정책, 선점(preemption) 등 더 강력한 스케줄링 기능을 제공하는 것이 핵심이다.
원래는 YARN과 K8s를 모두 겨냥했지만, 현재는 사실상 쿠버네티스 커스텀 스케줄러로 자리잡았다.
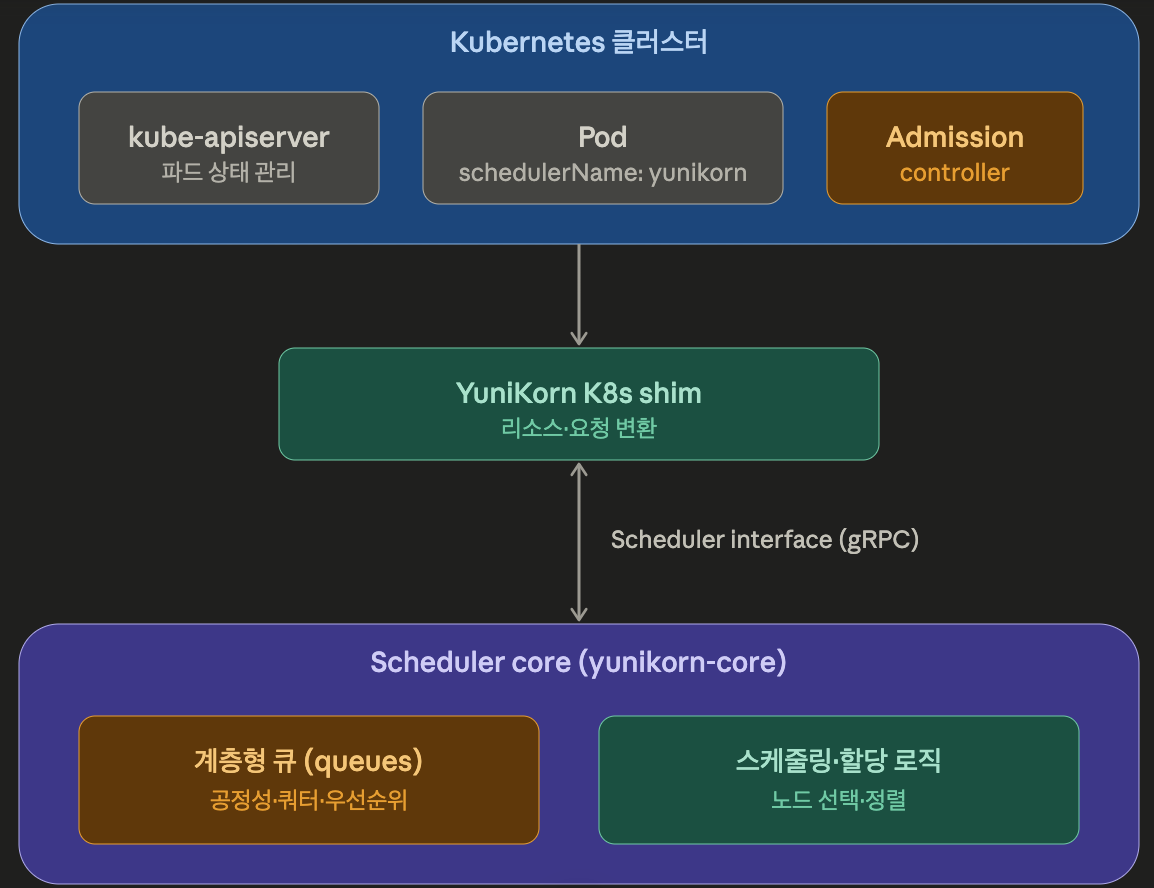
구조의 핵심은 두 컴포넌트로 나뉜다는 점이다. Scheduler core는 모든 스케줄링 알고리즘을 캡슐화하고, 하부 리소스 관리 플랫폼(K8s/YARN)으로부터 리소스를 수집해 컨테이너 할당 요청을 처리한다.
core의 모든 통신은 scheduler interface를 통해 이루어지며, 그 사이를 K8s shim이 연결하는데, shim은 쿠버네티스와 통신하며 클러스터 리소스와 리소스 요청을 scheduler interface 형식으로 번역해 core로 전달한다.
여기서 중요한건 admission controller 이다. 쿠버네티스 파드를 만들면, 그 요청이 곧바로 저장되는게 아니라 api 서버 입구를 한번 거치게 된다.
admission controller 는 바로 그 입구에 있다가, schedulerName: yunikorn을 끼워 넣어 준다.
그래서 클러스터의 모든 파드가 자동으로 YuniKorn으로 라우팅 되며, 아래와 같이 schedulerName을 추가해줄 필요가 없다.
# admission controller가 있을 때 — 입구에서 자동 주입되므로 생략 가능
spec:
containers:
- name: my-app
image: my-app:latest
# admission controller가 없을 때 — 파드마다 직접 지정해야 함
apiVersion: v1
kind: Pod
spec:
schedulerName: yunikorn # ← 이걸 깜빡하면 기본 스케줄러로 가버림
containers:
- name: my-app
image: my-app:latest
1-1) 계층형 큐(Hierarchical Queues)
YuniKorn 스케줄링의 중심 개념이며, 큐는 최상단 root 큐 아래에 자식 큐들이 붙은 계층 구조로 조직되며, 각 큐는 자체적인 리소스 보장(guaranteed)과 한도(max)를 가질 수 있다.
조직 구조(팀/테넌트)에 큐를 매핑해서 멀티테넌시와 쿼터를 구현하는게 전형적인 패턴이다.
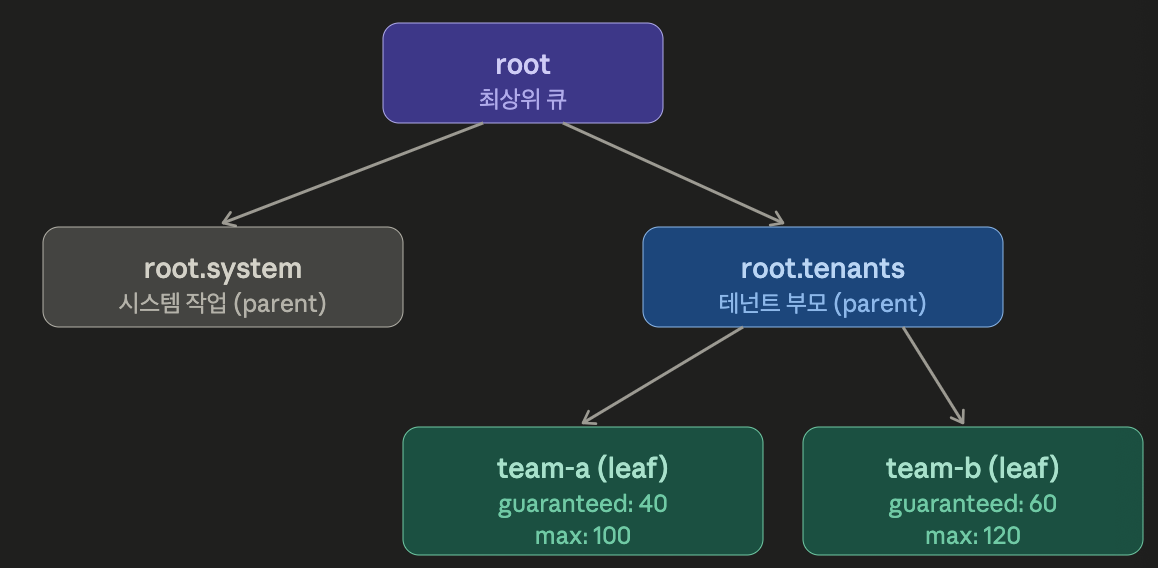
이 구조를 실제로 정의하는 건 yunikorn-configs ConfigMap이다.
기본적으로 스케줄러는 ConfigMap의 queues.yaml 섹션을 읽어 파티션과 큐 설정을 가져온다.
apiVersion: v1
kind: ConfigMap
metadata:
name: yunikorn-configs
namespace: yunikorn
data:
queues.yaml: |
partitions:
- name: default
queues:
- name: root
queues:
- name: system
parent: true # leaf를 강제로 parent로 지정
- name: tenants
parent: true
queues:
- name: team-a
resources:
guaranteed: {memory: 40G, vcore: 40}
max: {memory: 100G, vcore: 100}
properties:
application.sort.policy: fifo
- name: team-b
resources:
guaranteed: {memory: 60G, vcore: 60}
max: {memory: 120G, vcore: 120}
여기서 guaranteed는 최소 보장량이며, 큐의 안전지대이다.
공식 정의상 min-capacity = guaranteed, max-capacity = limit(quota/max)

위 그림과 같이 0 ~ guaranteed 영역은 항상 보장되며 선점당하지 않는다.
guaranteed ~ max 영역은 버스트 영역이며, 남는 자원을 빌려 쓸 수 있으나 회수(선점) 대상이 된다.
max 영역은 절대 넘지 못하는 영역이다.
버스트(burst) 영역은 내 몫은 아니지만, 지금 비어있으니 잠깐 빌려 쓰는 구간이다.
예를 들어 team-a가 guaranteed 40 코어, max 100 코어일 때, team-b가 자기 몫을 안 쓰고 놀고 있으면 team-a는 40 코어를 넘어 100 코어까지 빌려 쓸 수 있다.
덕분에 한 탐이 한가할 때 다른 팀이 그 여유를 흡수해서 클러스터 자원이 놀지 않는다.
이것이 각 팀에 자원을 딱 고정해두는 정적 쿼터보다 활용률이 높은 이유다.
단, 빌린 자원은 영구 소유가 아니다, 원래 주인(team-b)이 돌아와 자기 guaranteed를 요구하는데 빈 자원이 없으면, team-a가 빌려 쓰던 초과분이 회수된다. 이 회수 행위가 곧 preemption이다.
preemption은 버스트로 빌려 간 자원을, 원래 보장받아야 할 큐에게 돌려주는 회수 메커니즘이다.
즉, 실행중인 파드라도 회수 대상이 되면 종료될 수 있다. 다만 아무거나 빼앗는 것이 아니라, 정해진 규칙에 따라 동작한다.
회수는 강제 kill 이 아니라 쿠버네티스 표준 graceful termination 으로 종료한다.
여기서 회수하는 대상(victim 선정) 이 spark driver 라면, 잡 전체가 죽기 때문에 YuniKorn은 아래와 같은 완화 장치를 둔다.
# 드라이버 보호: 선점 금지 + 높은 우선순위
metadata:
labels:
applicationId: "spark-prod-001"
annotations:
yunikorn.apache.org/allow-preemption: "false" # 드라이버 선점 금지
spec:
priorityClassName: spark-prod-high # prod는 높은 우선순위
또한, 쿠버네티스 resourceQuota 와 달리, YuniKorn은 제출 시점이 아니라 실제 소비 시점에 쿼터를 적용한다.
즉, 새 파드는 항상 일단 수락되어 큐에 들어간다. 큐잉된 파드의 자원은 소비 쿼터로 집계되지 않는다.
스케줄링을 시도할 때 비로소 큐 쿼터에 맞는지 검사하고, 안 맞으면 그 파드는 건너 뛰게 되며 소비량을 집계하지 않는다.
결과적으로 기본 K8s 처럼 제출이 거부되는게 아니라, 자리가 날 때까지 Pending으로 대기한다.
이것이 자원 부족시 거부되어서 재시도를 추가로 해줘야 하는 문제를 피하게 해준다.
1-2) Placement Rules (큐 자동 배치)
어플리케이션을 큐에 동적으로 배치하는 규칙이며, 제출 시 큐를 명시하지 않아도, 규칙이 앱 정보(사용자명, 태그 등)를 이용해 큐를 결정한다.
placementrules:
- name: tag
value: namespace # 파드의 namespace → 큐 이름
create: true # 해당 큐 없으면 자동 생성
1-3) 작업 순서와 공정성 (FIFO / FAIR)
큐마다 application.sort.policy 를 지정한다.
- FIFO: 먼저 들어온 앱부터 처리
- FAIR: 사용량이 적은 앱/큐에 우선권을 줘 공정하게 분배
1-4) Gang Scheduling.
Spark 처럼 여러 파드가 함께 떠야 하는 워크로드의 경우 핵심 기능이며, 드라이버만 떠서 자원을 점유한 채 executor를 못 받으면 교착(resource deadlock)이 생기는데, gang scheduing은 필요한 최소 리소스가 한꺼번에 확보되지 않으면 아예 시작하지 않는 전략으로 이를 막는다.
--conf spark.kubernetes.driver.annotation.yunikorn.apache.org/task-groups='[
{"name": "spark-driver", "minMember": 1, "minResource": {"cpu": "1", "memory": "2Gi"}},
{"name": "spark-executor", "minMember": 10, "minResource": {"cpu": "1", "memory": "2Gi"}}
]'
--conf spark.kubernetes.driver.annotation.yunikorn.apache.org/schedulingPolicyParameters='placeholderTimeoutInSeconds=300 gangSchedulingStyle=Soft'
단, 주의해야할점은 gang 앱이 도는 큐는 FIFO 여야 한다.
FAIR 큐에 gang 앱을 제출하면 거부한다.
FAIR 는 여러 New 어플리케이션을 동시에 할당해 쿼터 관리를 불가능하게 만들고, 부분적으로만 보장된 앱이 여럿 생길 수 있으며, 오토스케일로 늘어난 노드를 placeholder 대신 다른 앱이 가져가 gang이 깨질 수 있기 때문이다.
gang은 필요한 멤버가 한꺼번에 다 모여야 시작하는 방식이고, 이걸 위해 placeholder로 자리를 잡아두고 기다린다. 그런데 FAIR 정렬은 여러 앱을 조금씩 공평하게 동시에 진행시키려는 성격이라 한꺼번에 몰아주기가 필요한 gang과 철학과 다르다.
Gang Scheduling 사용시 FIFO 약점은 큰 잡이 자기 자원을 다 확보하지 못해서 앞에서 대기하느라 뒤에 작은 잡들이 기다리는 상황이 있다.
이를 위한 보완책은 첫번째로 워크로드 별로 큐를 나누는 것이다.
둘때, maxapplications로 한 큐 안에 동시 실행 수를 제한해 동시에 running 상태인 앱의 개수를 제한하는 것이다.
동시에 너무 많은앱이 떠서 자원이 얇게 쪼개지는 것을 막는다.
- name: team-a
maxapplications: 10 # 이 큐에서 동시에 도는 앱은 최대 10개
resources:
guaranteed: {memory: 200G, vcore: 100}
max: {memory: 400G, vcore: 200} # 자원 상한은 여기서 (앱 독점 방지)
properties:
application.sort.policy: fifo
일반적으로 Spark on YuniKorn 에서는 gang을 켜는게 표준이고, 그 결과 leaf 큐는 FIFO가 기본값이자 필수이다. 공정성은 FAIR가 아니라 큐 계층, 쿼터, 큐 간 선점으로 설계하는게 권장된다.
Reference
https://spark.apache.org/docs/latest/running-on-kubernetes.html
https://medium.com/@titieiti.com/airflow-kubernetesexecutor%EC%99%80-kubernetespodoperator-19d470e40a1e
https://github.com/fabric8io/kubernetes-client/blob/v6.4.1/kubernetes-client-api/src/main/java/io/fabric8/kubernetes/client/Config.java