이번글에서는 아파치 카프카의 새로운 메커니즘인 KRaft를 자세히 살펴볼 예정이다.
KRaft를 사용하면 메타데이터를 효율적으로 관리할 수 있다. KRaft는 주피커의 의존성을 제거하고, 카프카 클러스터 내 컨트롤러가 선출된 후 메타데이터를 직접 괸리한다. 이로 인해 성능과 안정성이 향상되며, 유지보수가 단순화되고 병목현상이 줄어든다.
1. KRaft의 등장과 배경
KRaft(Kafka Raft)는 아파치 카프카의 분산 시스템을 관리하기 위해 도입된 새로운 메커니즘이다.
이전까지는 카프카는 아파치 주키퍼(Apache ZooKeeper)를 사용하여 클러스터 메타데이터의 관리와 조정을 담당했다. 그러나 주피커의 의존성은 카프카의 확장성과 유지보수에 여러 제약을 가져왔고, 이를 해결하기 위해 카프카 자체 내에서 분산 시스템의 상태를 관리하는 방식을 도입하기로 결정했다.
주키퍼 사용 시 이슈가 되는 부분들에 대해 자세히 살펴보면 아래와 같다.
1-1) 성능적인 부분
주키퍼를 사용하면서 여러가지 불편, 제한적인 상황이 있었겠지만 카프카에서
새로운 방식의 메커니즘 도입을 결정하는데, 아마도 성능적인 이슈가 가장 큰 영향을 받았을 것이다.
브로커는 모든 토픽과 파티션에 대한 메타데이터를 주키퍼에서 읽어야 하며, 메타데이터의 업데이트는 주키퍼에서 동기 방식으로 일어나고 브로커에는 비동기방식으로 전달되었다.
이 과정에서 메타데이터의 불일치가 발생할 수도 있으며, 컨트롤러 재시작 시 모든 메타데이터를 주키퍼로부터 읽어야 하는 것도 부담이었다.
특히 토픽과 파티션이 많은 대규모 카프카 클러스터에서는 오랜 시간이 걸리는 등 병목현상이 발생할 수 있다.
1-2) 관리적인 부분
주키퍼와 카프카는 완전히 서로 다른 어플리케이션으로 서로 다른 구성 파일, 환경, 서비스 데몬을 가지고 있다.
결국 관리자는 동시에 서로 다른 어플리케이션을 운영해야 하며, 동시에 두 가지 어플리케이션을 운영한다는 것은 관리자에게 큰 부담이 된다.
예를 들면 주키퍼의 릴리스 노트 확인, 버전 업그레이드, 구성 파일 변경과 동시에 카프카의 릴리즈 노트 확인, 버전 업그레이드, 구성 파일 변경을 해야 한다.
1-3) 모니터링
모든 서비스는 모니터링이 필수이며, 주키퍼와 카프카 둘 다 모니터링을 해야 한다.
두 어플리케이션은 서로 다른 어플리케이션으로 모니터링을 적용하는 방법과 각 어플리케이션에서 보여주는 주요 메트릭도 다르다.
또한 모니터링에 필요한 필수 메트릭을 이해하고 모니터링하는 방법까지 완전히 다르다.
당연히 각각의 어플리케이션 별 장애 대응도 해야 하기 때문에 관리 및 유지보수 비용이 추가로 들게 된다.
2. KRaft 의 주요 목적
KRaft의 주요 목적은 카프카의 구조를 단순화하고 확장성을 향상시키기 위함이다.
앞에서 언급한 여러 불편한 부분들이 주키퍼를 제거함으로써 설치, 구성, 유지보수가 단순화될 뿐만 아니라 카프카의 성능과 안정성 역시 크게 향상될 수 있다.
즉, KRaft를 카프카와 결합하여 운영 복잡성을 줄이고, 데이터 플랫폼의 중추 역할을 하는 카프카의 전반적인 신뢰성과 관리 용이성을 개선하는데 기여할 수 있다.
3. 주키퍼 모드 vs KRaft 모드
이제부터는 카프카 클러스터에서 주키퍼 모드와 KRaft 모드에 대한 차이점을 살펴보자.
3-1) 주키퍼 모드
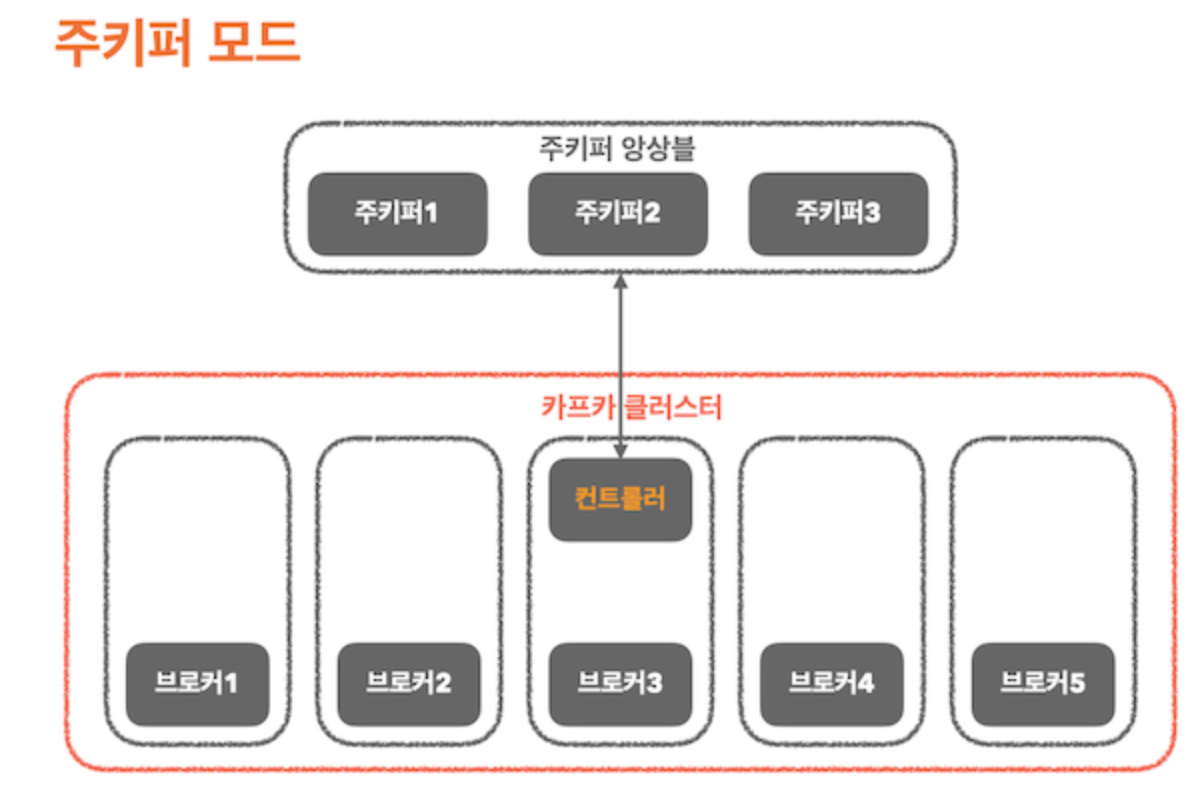
주키퍼 모드는 주키퍼 앙상블(Ensemble)과 카프카 클러스터가 존재하며, 카프카 클러스터 중 하나의 브로커가 컨트롤러 역할을 하게 된다.
컨트롤러는 파티션의 리더를 선출하는 역할을 하며, 리더 선출 정보를 브로커에게 전파하고 주키퍼에 리더 정보를 기록하는 역할을 한다.
컨트롤러의 선출 작업은 주키퍼를 통해 이루어 지는데, 주키퍼의 임시노드를 통해 이루어진다.
임시노드에 가장 먼저 연결에 성공한 브로커가 컨트롤러가 되고, 다른 브로커들은 해당 임시노드에 이미 컨트롤러가 있다는 사실을 통해 카프카 클러스터 내 컨트롤러가 있다는 것을 인식하게 된다.
이를 통해 한번에 하나의 컨트롤러만 클러스터에 있도록 보장할 수 있다.
3-2) KRaft 모드
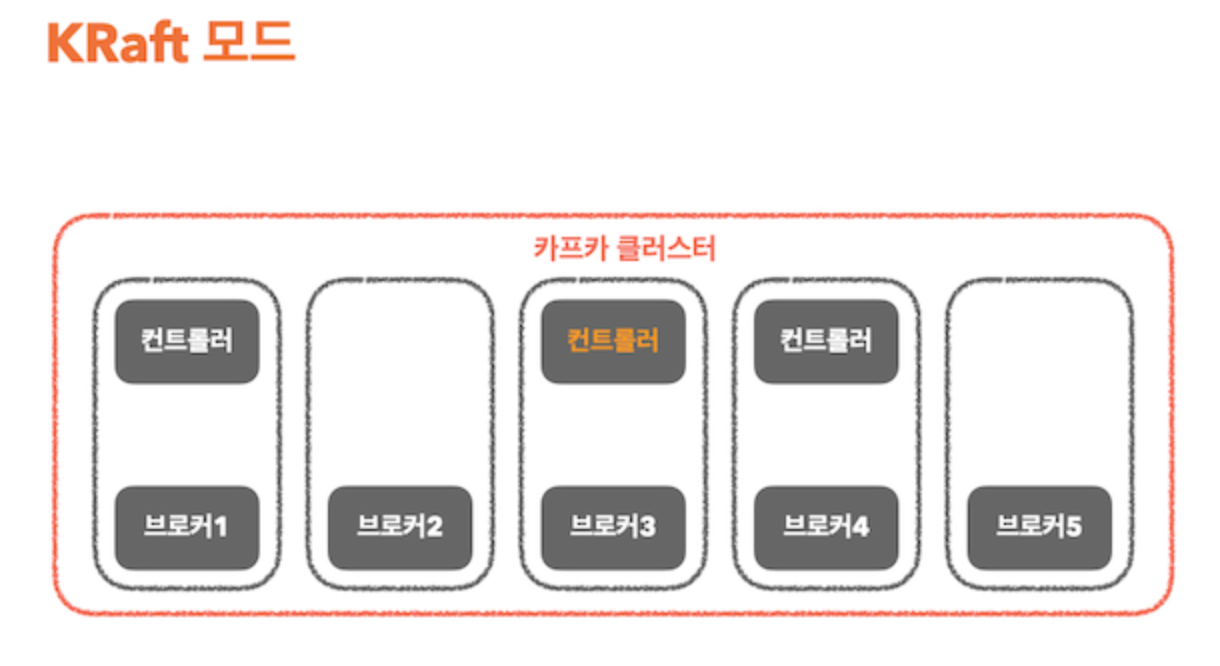
위 그림에서 보는 바와 같이 KRaft 모드에서는 주키퍼가 사라진 것을 알 수 있다.
주키퍼 모드에서 1개였던 컨트롤러가 3개로 늘어나고, 이들 중 하나의 컨트롤러가 액티브(그림에서는 노란색 컨트롤러) 컨트롤러이면서 리더 역할을 담당한다.
리더 역할을 하는 컨트롤러가 write 하는 역할도 하게 된다.
또한 주키퍼 노드에서는 메타 데이터 관리를 주키퍼가 했다면, 이제는 카프카 내부의 별도 토픽을 이용하여 메타 데이터를 관리한다.
액티브인 컨트롤러가 장애 또는 종료되는 경우, 내부에서는 새로운 합의 알고리즘을 통해 새로운 리더를 선출하게 된다.
리더를 선출하는 과정을 간략히 설명하면, 후보자들은 적합한 리더를 투표하게 되고 후보자 중 충분한 표를 얻으면 해당 컨트롤러가 새로운 리더가 된다.
4. KRaft 의 성능
KRaft의 주요 성능 개선 중 하나는 파티션 리더 선출의 최적화이다.
위에서 언급한것처럼 컨트롤러의 주요 역할은 파티션의 리더를 선출하는 것이다. 소수의 파티션에 대한 리더 선출 작업은 카프카 또는 카프카를 사용하는 클라이언트들에게 별다른 영향이 없겠으나, 대량의 파티션에 대한 리더 선출 작업은 다소 시간이 소요되며 이러한 시간은 대량의 데이터 파이프라인의 역할을 하는 카프카 클라이언트들에게 매우 크리티컬한 요소 일 수 있다.
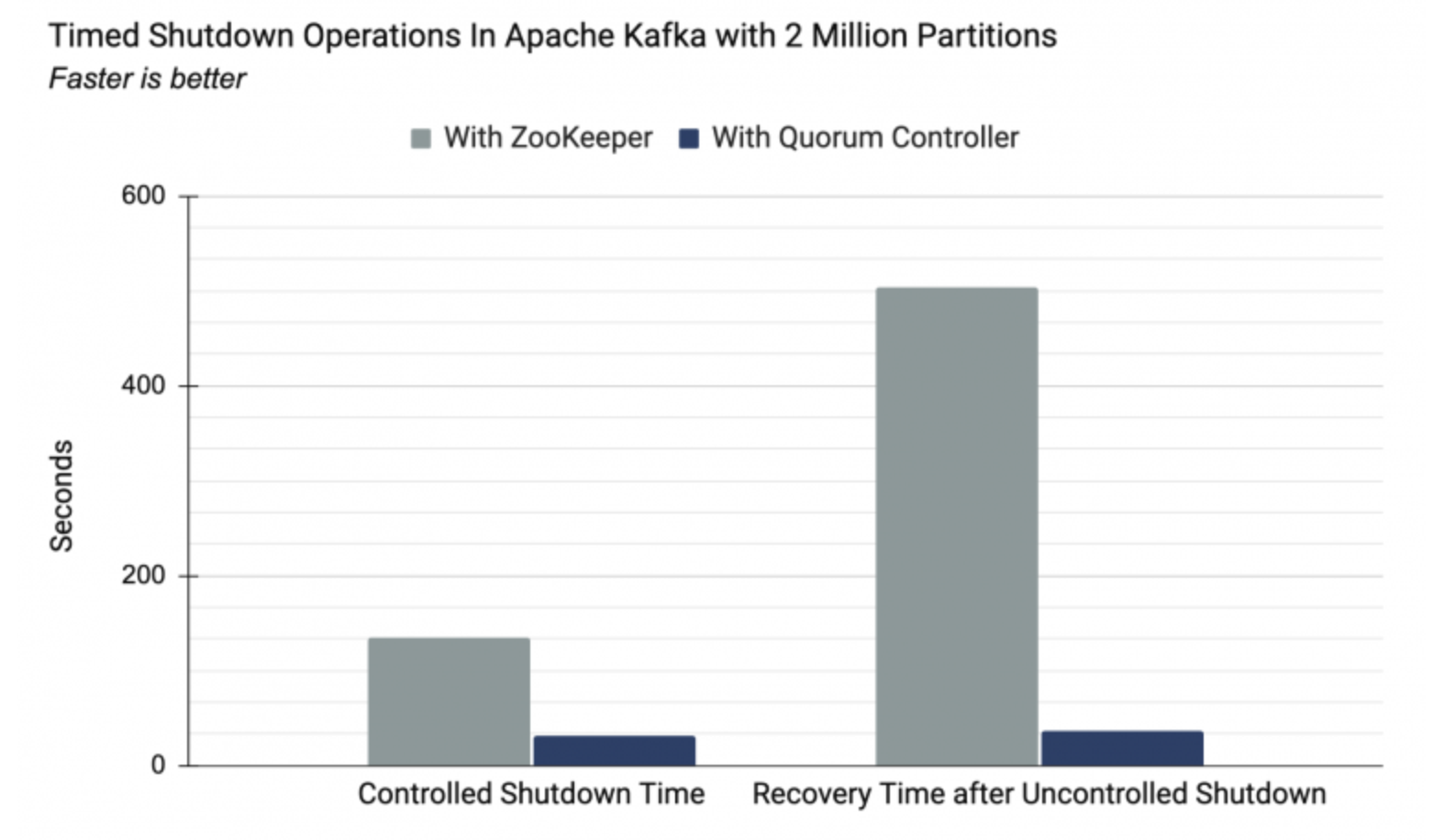
confluent 에서 공개한 KRaft 모드와 주키퍼 모드 간의 속도를 비교한 그림을 살펴보면, 복구 소요시간에서 엄청난 차이를 나타내고 있음을 알 수 있다.
이렇게 속도차이가 나는 이유는 KRaft 모드에서는 컨트롤러는 메모리 내에 메타데이터 캐시를 유지하고 있으며, 주키퍼와의 의존성도 제거해 내부적으로 메타데이터의 동기화와 관리과정을 효율적으로 개선했기 때문이다.
또한 액티브 컨트롤러 장애 시 최신 메타데이터가 메모리에 유지되고 있으므로, 메타데이터 복제하는 시간도 줄어들어 보다 효율적인 컨트롤러 리더 선출 작업이 일어난다.
Reference
https://devocean.sk.com/blog/techBoardDetail.do?ID=165711&boardType=techBlog
https://devocean.sk.com/blog/techBoardDetail.do?page=&boardType=undefined&query=&ID=165737&searchData=&subIndex=&searchText=&techType=&searchDataSub=&searchDataMain=&comment=&p=