1. 개발 환경 설정
먼저 파이썬 인터프리터 버전 3.10.11 를 설치해보자.
설치 완료 후/usr/local/bin 디렉토리에 python3.10 관련 파일이 생성됨을 확인할 수 있다.
그 후 파이썬 가상 환경을 생성해보자.
$ cd ~/dev
$ mkdir datalake
$ cd datalake
# kafka_venv 이름의 디렉토리가 생성되면서 가상환경 생성
$ /usr/local/bin/python3.10 -m venv kafka_venv
$ cd kafka_venv
# kafka_venv 가상환경으로 진입
$ source bin/activate
$ python -V
# 파이썬 가상환경을 빠져나올 때는 현재 위치한 경로에 상관없이 deactivate
$ deactivate
2. 카프카 클러스터 구성하기
카프카 클러스터 구성은 NAT 인스턴스 기반으로 진행할 예정이며, 먼저 NAT에 대해서 살펴보자.
2-1) NAT(Network Address Translation) 란?
내부망에 연결된 장비의 IP를 1개 또는 소수의 외부 IP로 변환하는 기술부족한 IPv4 공인 1개를 받은 후 사설 IP 수십개와 매핑 가능하며 외부에서 먼저 접근할 수 없으므로 보안적으로도 우수하여 기업내에서도 자주 사용되는 기술
IPv4 가 고갈된다고 한지가 20년이 넘었지만 아직도 잘사용하고 있는 이유가 NAT 기술 때문이다.
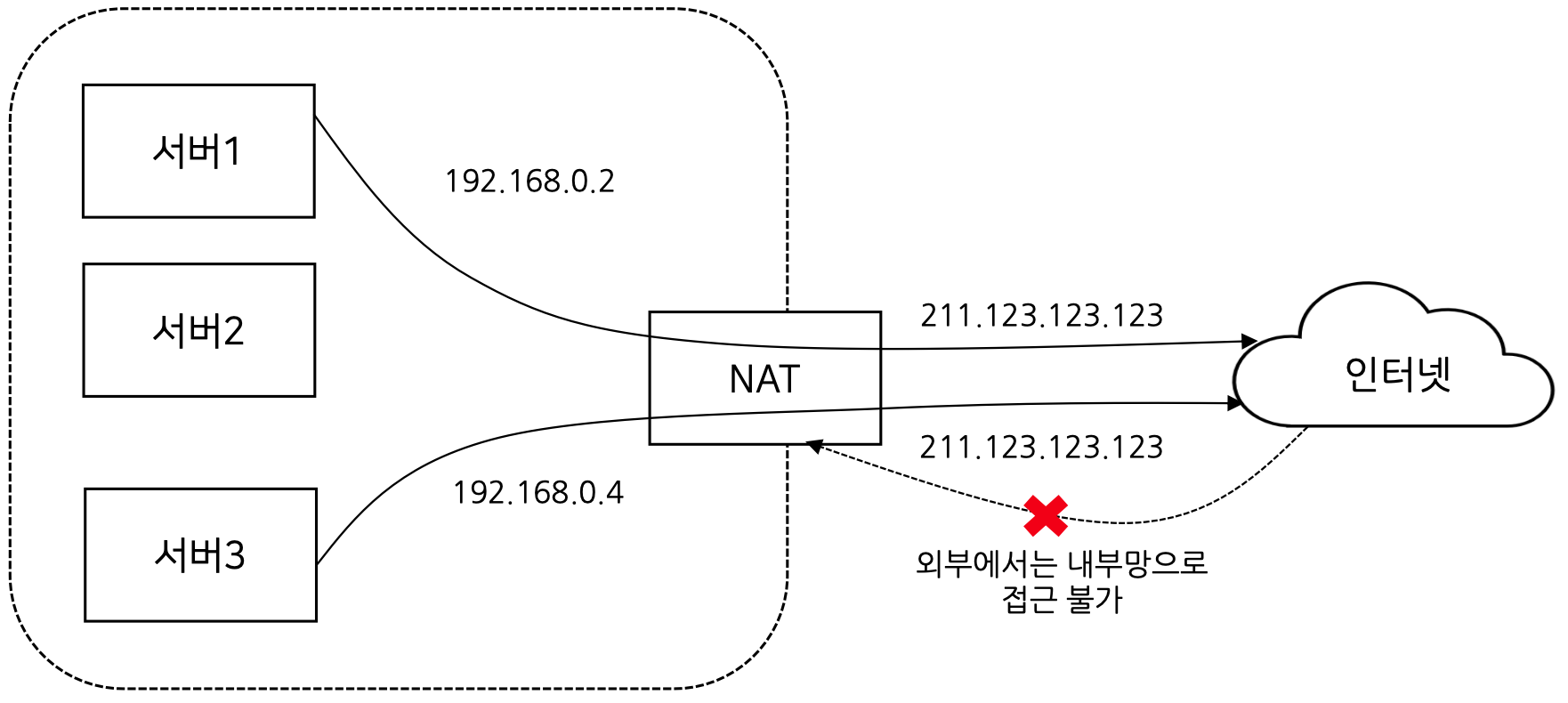
집에서 공유기 사용할 때도 NAT 를 사용하게 되며 컴퓨터, 노트북, 핸드폰 등이 연결이 되어 모두 사설 IP로 할당이 되어 있다.
사설 IP로 할당이 되고 외부 인터넷 등을 연결할 때 NAT 가 공인 IP 로 변경해주게 된다.
그리고 컨텐츠 등을 들고 다시 돌아올때는 이를 다시 사설 IP로 바꿔주게 된다.
따라서 NAT가 있음으로써 사설 IP가 외부에 접근하여 돌아오게는 가능하지만, 반대로 외부에서 직접 접근이 불가능하게 하여 보안을 향상 시킬 수 있다.
2-2) AWS NAT 인스턴스 기반 카프카 클러스터
private subnet 에서 인터넷 연결을 하기 위해 AWS NAT Gateway 서비스가 존재한다.
하지만 NAT Gateway 는 상대적으로 고비용, 고가용성 서비스이기 때문에 실습을 위해 EC2를 이용한 NAT Instance를 구성해 볼 예정이다.
NAT 역할을 하는 EC2를 구성하며, NAT Gateway와 동일한 역할을 한다.
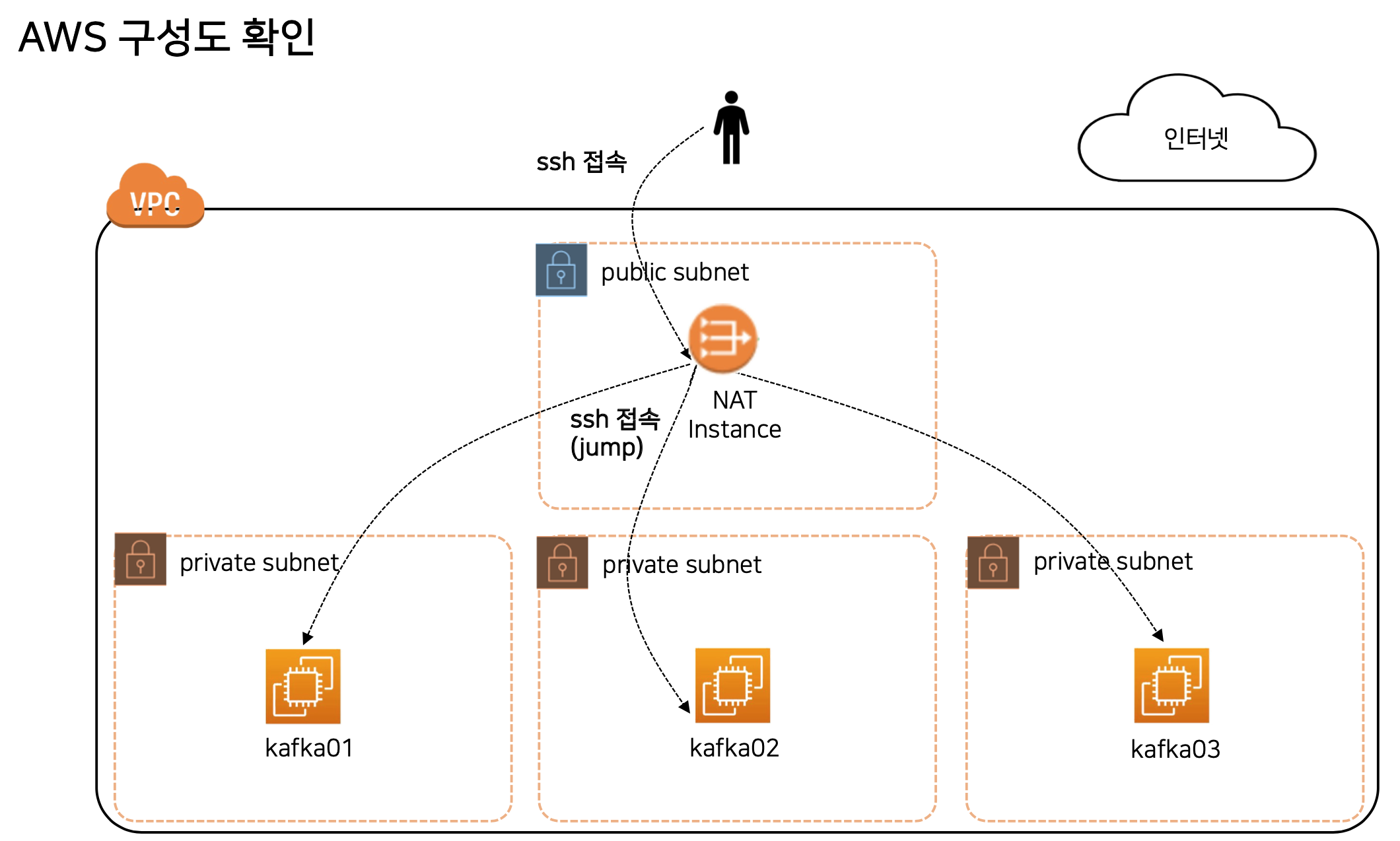
위 구성도를 보면 인터넷 접속이 가능한 public subnet 이 있으며, EC2 기반 NAT 인스턴스로 구성했다.
각 private subnet은 인터넷을 통해 직접 접근이 불가능하며,
public subnet을 통해서만 접근이 가능하도록 구성했다.
또한, private subnet에 있는 kafka 등이 인터넷 접속이 필요할 때도 동일하게 public subnet을 통해서만 접근이 가능하다.
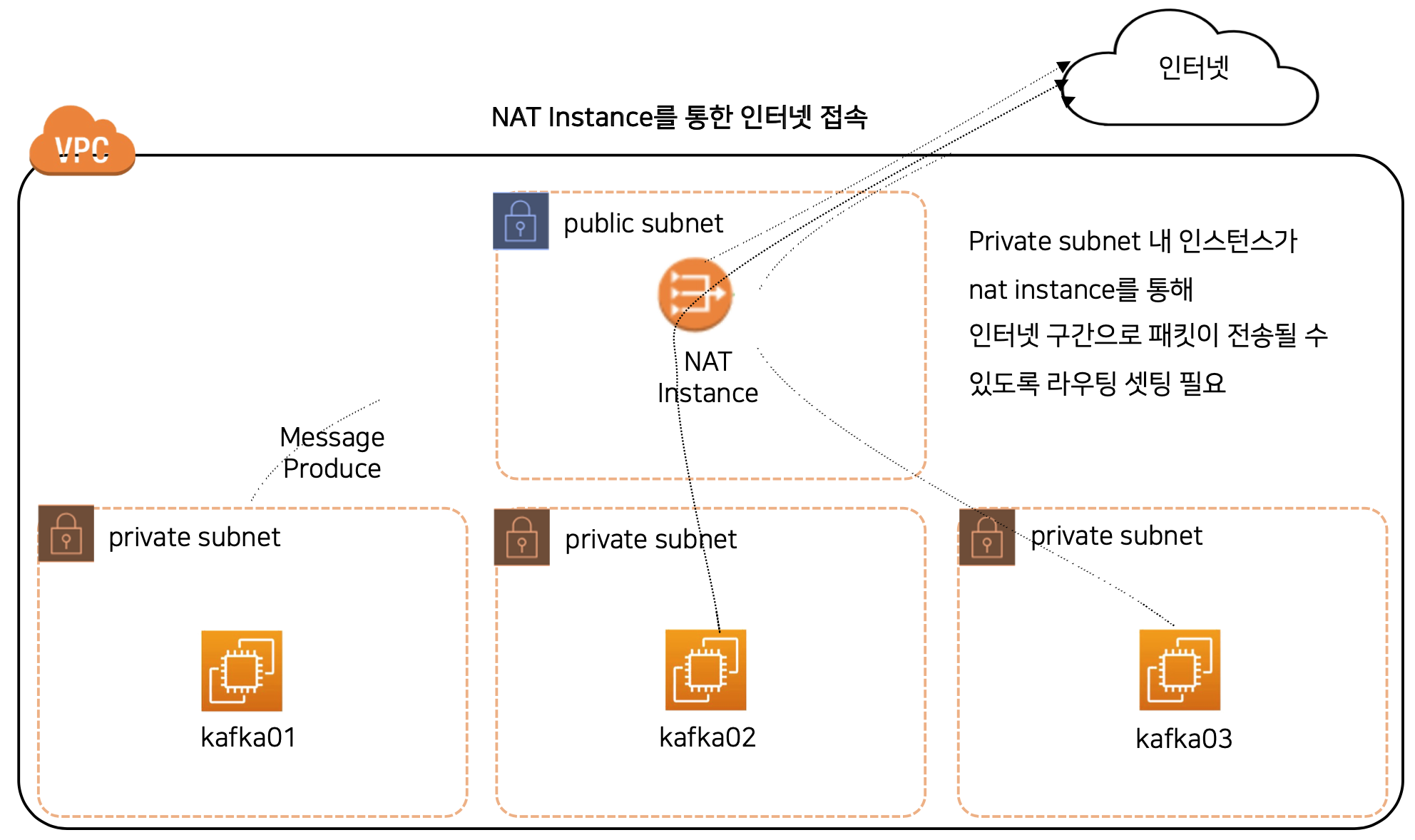
링크를 참고하여 구성해보자.
3. Confluent Kafka 를 이용하여 파이썬으로 구현하기
아파치 카프카는 자바로 구현되어 있지만, Client(Producer, Consumer)는 파이썬과 같은 다른 언어로 구현이 가능한 여러 라이브러리가 존재한다.
파이썬으로 Kafka Client 구현이 가능한 라이브러리 예는 아래와 같다.
- confluent-kafka:
Confluent의 공식 라이브러리, librdkafka 라이브러리 기반이며 가장 성능이 좋다. - kafka-python: pure 파이썬으로 작성되어 있으며 가장 성능이 느리다.
- pykafka: kafka-python 대비 성능이 좋다.
- aiokafka: 파이썬의 asyncio 라이브러리 기반 동작하며, kafka-python(동기방식) 대비 성능이 좋다.
이 글에서는 Confluent Kafka 를 사용할 것이며,
Zookeepr를 포함하고 있는 Apache Kafka 2.8x, Confluent Platform 6.2x 버전을 사용할 예정이다.
그 이후 버전부터는 Zookeeper를 제외한 KRaft 합의 알고리즘을 사용한다.
Confluent 사는 실리콘밸리에 있는 빅데이터 회사로, 아파치 카프카의 최초 개발자들(Jay Kreps 등)이 설립한 회사이다.
파이썬은 내부적으로 librdkafka를 활용하여 구동되며, librdkafka 라이브러리는 순수 자바 Kafka 와 비교했을 때 옵션에 대해서 차이가 존재 한다.
librdkafka는 C 언어를 기반으로 만들어진 라이브러리이다.
Broker 옵션 과 Topic 옵션, Producer 옵션, Consumer 옵션 등은 기존 아파치 카프카와 다른 옵션이 존재하기 때문에 공식문서를 참고하자.
아래 코드는 producer 기본 예시이며, 비동기 방식으로 publish를 진행하고 있다.
class SimpleProducer:
def __init__(self, topic, duration=None):
self.topic = topic
self.duration = duration if duration is not None else 60
self.conf = {'bootstrap.servers': BROKER_LST}
self.producer = Producer(self.conf)
# Optional per-message delivery callback (triggered by poll() or flush())
# when a message has been successfully delivered or permanently
# failed delivery (after retries).
def delivery_callback(self, err, msg):
if err:
sys.stderr.write('%% Message failed delivery: %s\n' % err)
else:
sys.stderr.write('%% Message delivered to %s [%d] @ %d\n' %
(msg.topic(), msg.partition(), msg.offset()))
def produce(self):
cnt = 0
while cnt < self.duration:
try:
# Produce line (without newline)
self.producer.produce(
topic=self.topic,
key=str(cnt),
value=f'hello world: {cnt}',
on_delivery=self.delivery_callback)
except BufferError:
sys.stderr.write('%% Local producer queue is full (%d messages awaiting delivery): try again\n' %
len(self.producer))
# Serve delivery callback queue.
# NOTE: Since produce() is an asynchronous API this poll() call
# will most likely not serve the delivery callback for the
# last produce()d message.
self.producer.poll(0)
cnt += 1
time.sleep(1) # 1초 대기
# Wait until all messages have been delivered
sys.stderr.write('%% Waiting for %d deliveries\n' % len(self.producer))
self.producer.flush()
producer는 메시지 전송에 대해서 바로 진행하지 않고 메모리 공간 내에
buffer 설정 만큼 쌓아 두었다가 한번에 브로커에 전달한다.
옵션은 linger.ms 이며, linger의 의미는 꾸물거리다 이다.
그 후 브로커는 정상적으로 메시지를 전달 받았다면 ack 응답을 리턴해준다.
여기서 동기식 방식이라면 ack 응답을 받을 때까지 기다린 후 다음 메시지를 처리하지만
비동기 방식이라면 ack 응답을 쌓아두고 주기적으로 한번에 처리하게 된다.
따라서, 비동기 방식일 경우 위의 예시와 같이 반드시 callback 함수를 정의를 해주어야 하며, poll() 호출을 통해 callback 결과를 꺼내와야 한다.
비동기 방식일 경우 poll() 함수를 주기적으로 호출하여 메모리에 쌓인 ack 응답값들을 비워주어야 한다.
자바 기반 아파치 카프카의 경우 send() 함수는 poll 과정이 백그라운드로 수행되기 때문에 직접 구현해줄 필요는 없다.
마지막으로 flush() 함수는 동기식 방식, 비동기방식 모두 프로그램이 끝나기 직전에 호출해주어야 한다.
위에서 buffer 설정 만큼 메모리에 메시지를 쌓아두고 처리를 하게 되는데
프로그램 종료 직전에 메시지가 남아 있는 경우 처리를 해주어야 하기 때문이다.
4. Producer 메커니즘과 성능
producer 성능 튜닝 및 옵션 이해를 위해 동작 메커니즘을 이해하는 것이 중요하며, 자바 기반인 아파치 카프카와 Confluent Kafka 를 각각 비교해보자.
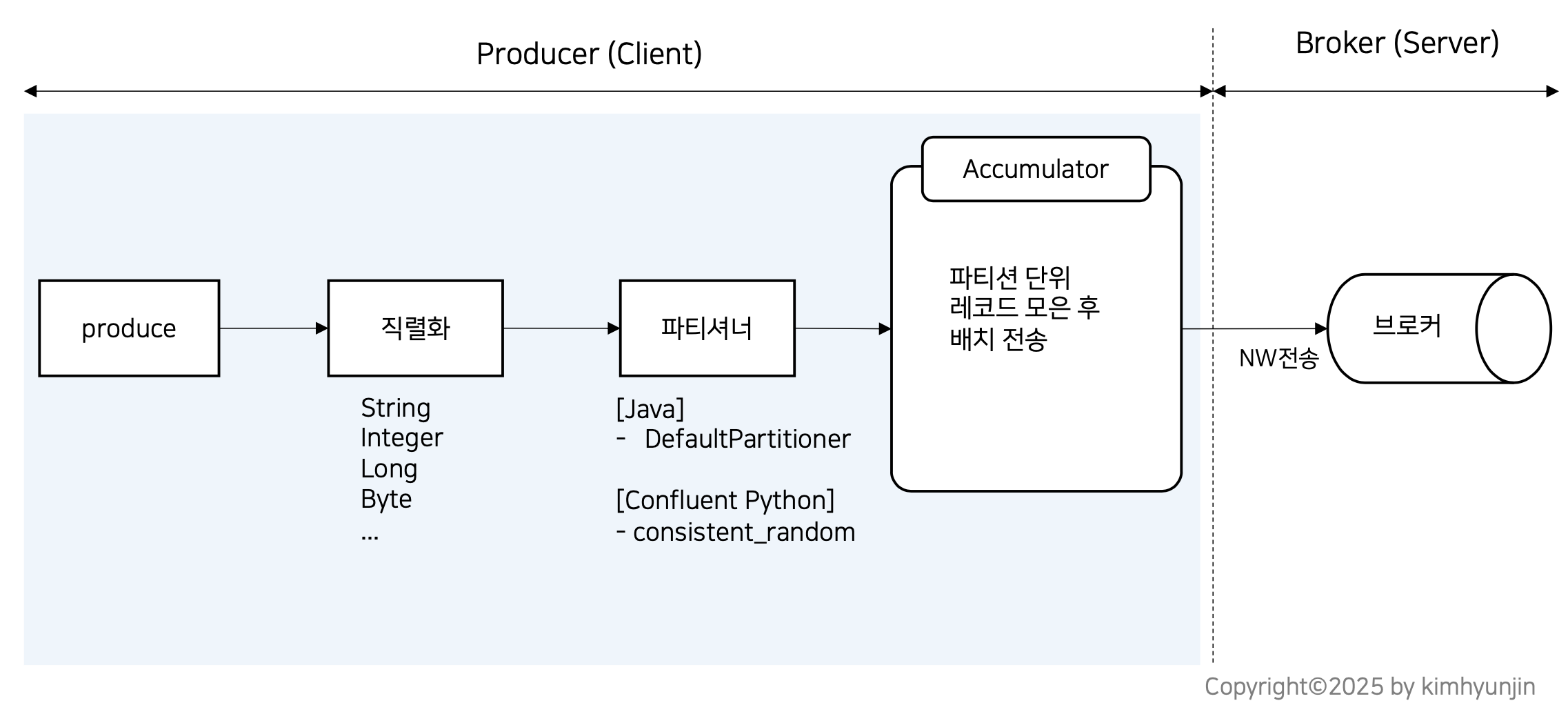
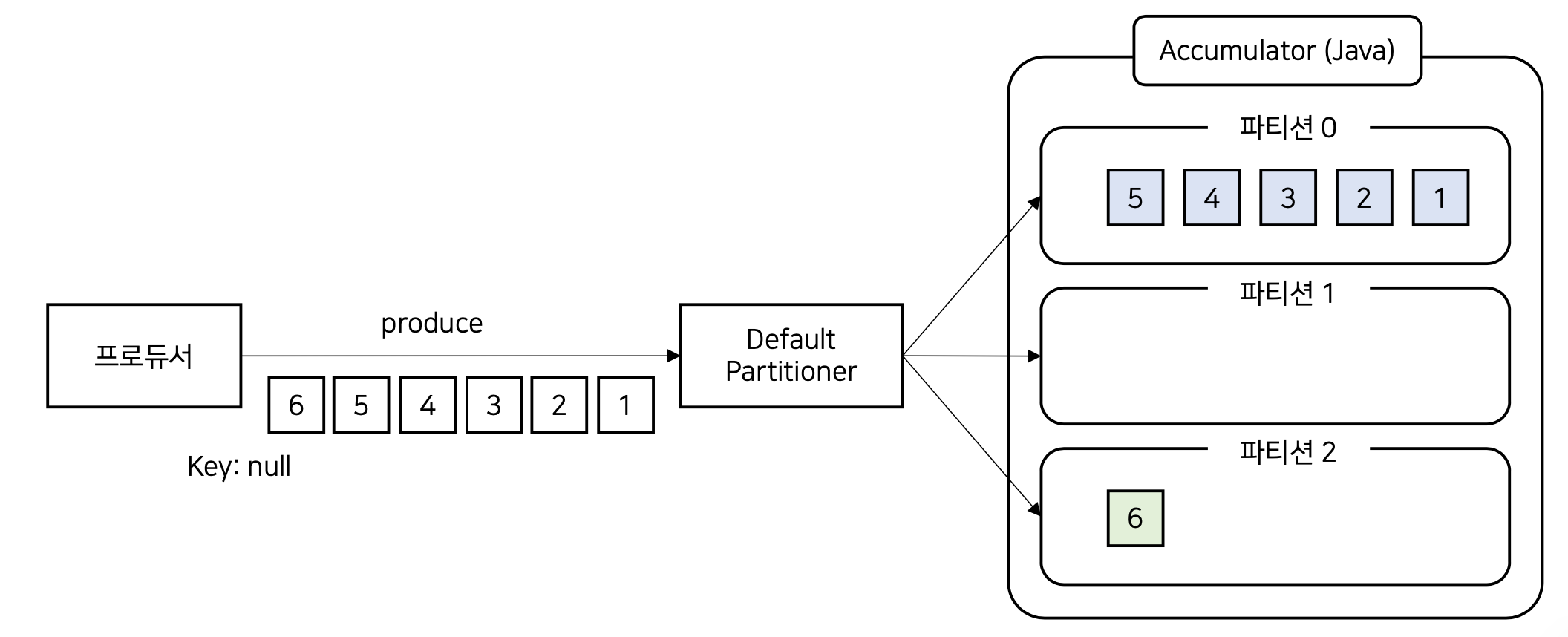
위의 그림과 같이 자바에서와 confluent kafka 가 사용하는 파티셔너가 다르다.
Accumulator 라는 메모리 객체는 자바에서 부르는 용어이며, Confluent Kafka의 경우 단순히 Queue라 부르나 원리는 동일하다.
Producer가 produce 메서드 호출시(자바에서는 send) 브로커로 즉시 전송되는 것이 아니라 Accumulator에 어느 정도 모은 후 전송한다.
4-1) Producer 성능 관련 파라미터
Confluent Kafka Python의 전체 파라미터는 링크에서 확인 가능하며, 자바 기반 아파치 카프카와 옵션을 비교해보자.
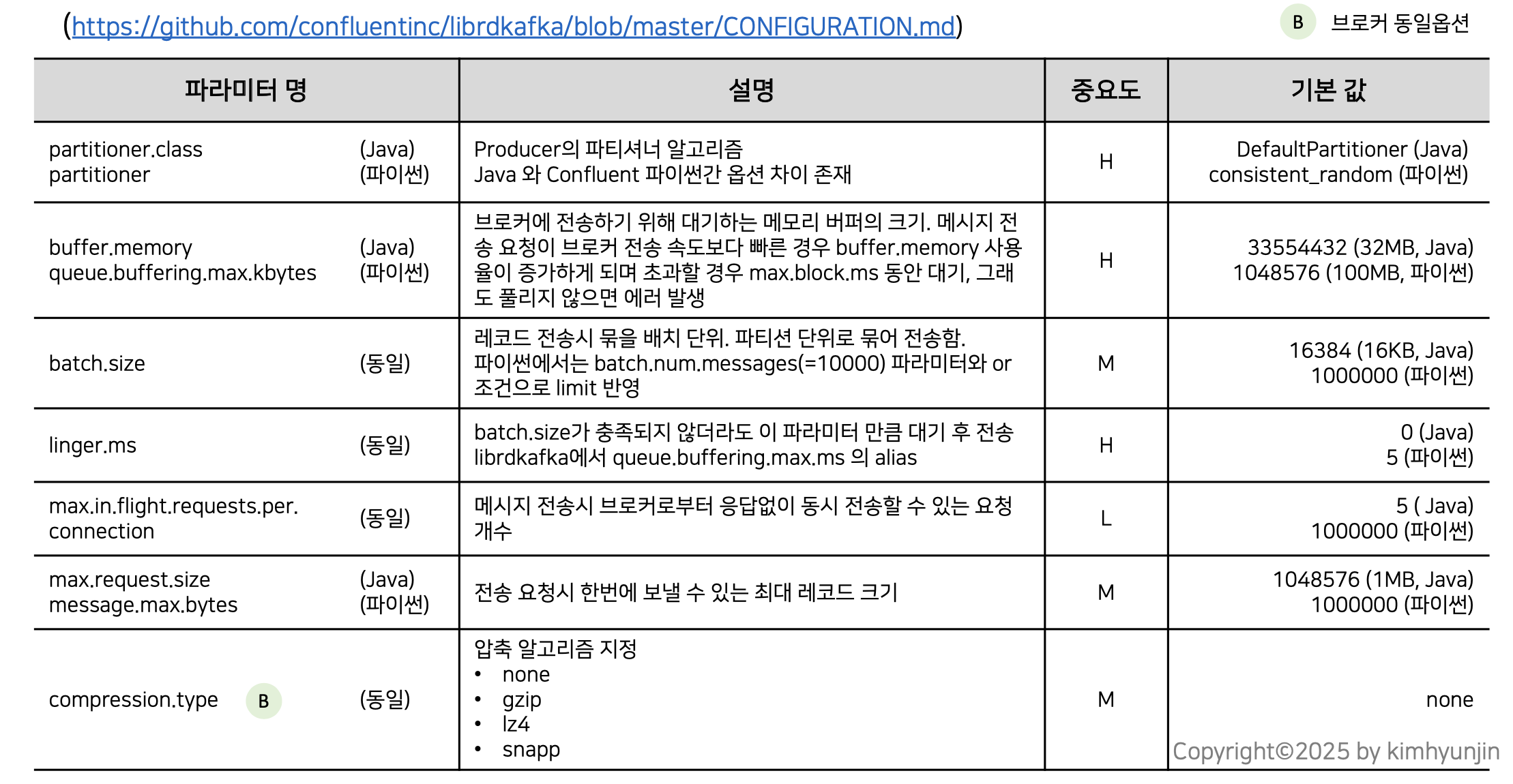
위 옵션 중 중요한 max.in.flight.requests.per.connection 를 살펴보자.
kafka는 레코드들을 묶어서 전송한다고 했고, 이를 전송시 브로커로부터 응답없이 동시에 전송할 수 있는 요청의 개수이다.
이 설정 값이 5로 설정되어 있다고 할 때, 레코드 묶음 단위(버스)를 전송하다가 중간의 묶음 단위가 실패할 경우 재처리를 진행하게 되며, 이때 순서가 변경될 수 있다.
이 옵션은 Accumulator 단위가 아니라 파티션 단위 내에서의 레코드의 묶음이 대상이 된다.
또한, max.request.size 는 Accumulator 단위로 전송 요청시 한번에 보낼 수 있는 최대 레코드의 크기이다.
batch.size는 버스 크기 이며, max.request.size는 브로커로 전달되고 있는 버스들의 총 크기라고 생각하면 된다.
전체 Producer 내부 구조와 옵션은 아래 그림으로 이해해보자.
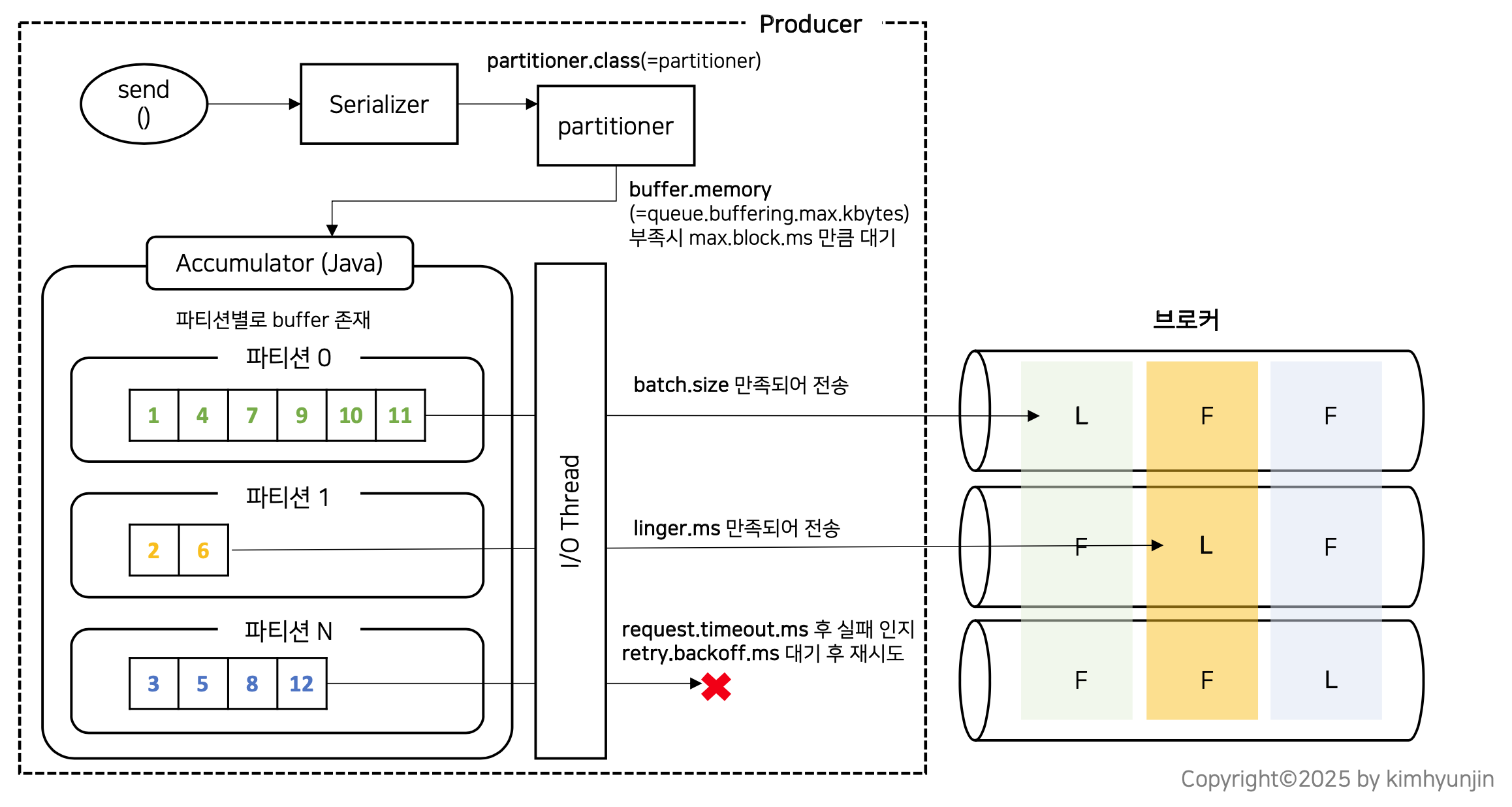
위에서 레코드의 묶음(버스)를 브로커에 전송했는데, 응답이 오지 않는다면 request.timeout.ms 만큼 기다린 후 retry.backoff.ms 만큼 대기 후 재시도를 하게된다.
4-2) 자바 기반 apache kafka의 파티셔너
자바에서는 DefaultPartitoner 클래스가 기본 지정되며 필요시 Custom Partitoner 를 만들어서 사용이 가능하다.
Default Partitioner 에서도 메시지 Key가 존재할 때와 null 일때로 나뉜다.
메시지 key가 존재할 때는 key 값 기반 hash 알고리즘(murmur2)에 의해 파티션이 결정된다.
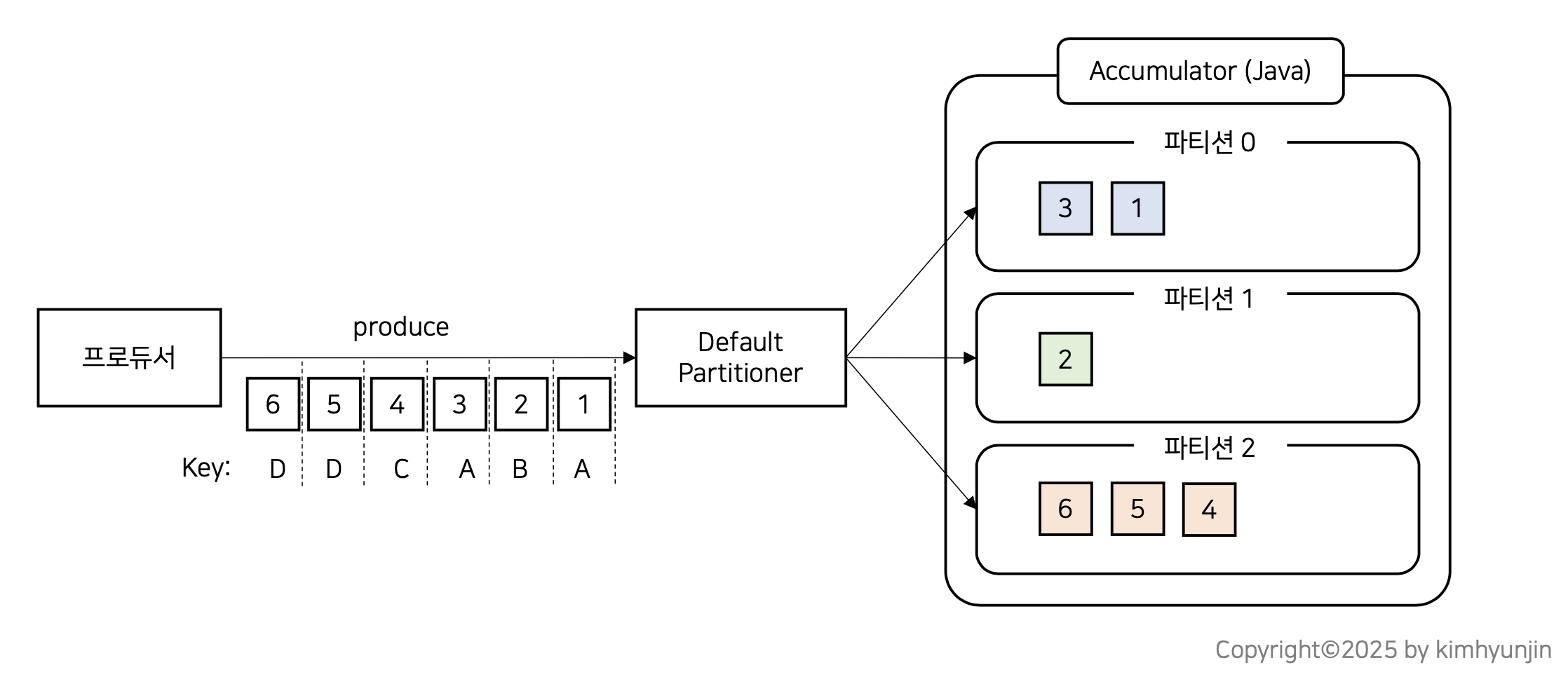
같은 키값은 모두 같은 파티션으로 전달된다.
반면에 메시지 key가 null일 경우는 버전에 따라 다르며, 2.4 하위 버전은 라운드 로빈 방식(Round-Robin)이며, 2.4 이상 버전은 유니폼 스티키 파티셔닝(Uniform Sticky Partitioning) 을 사용하게 된다.
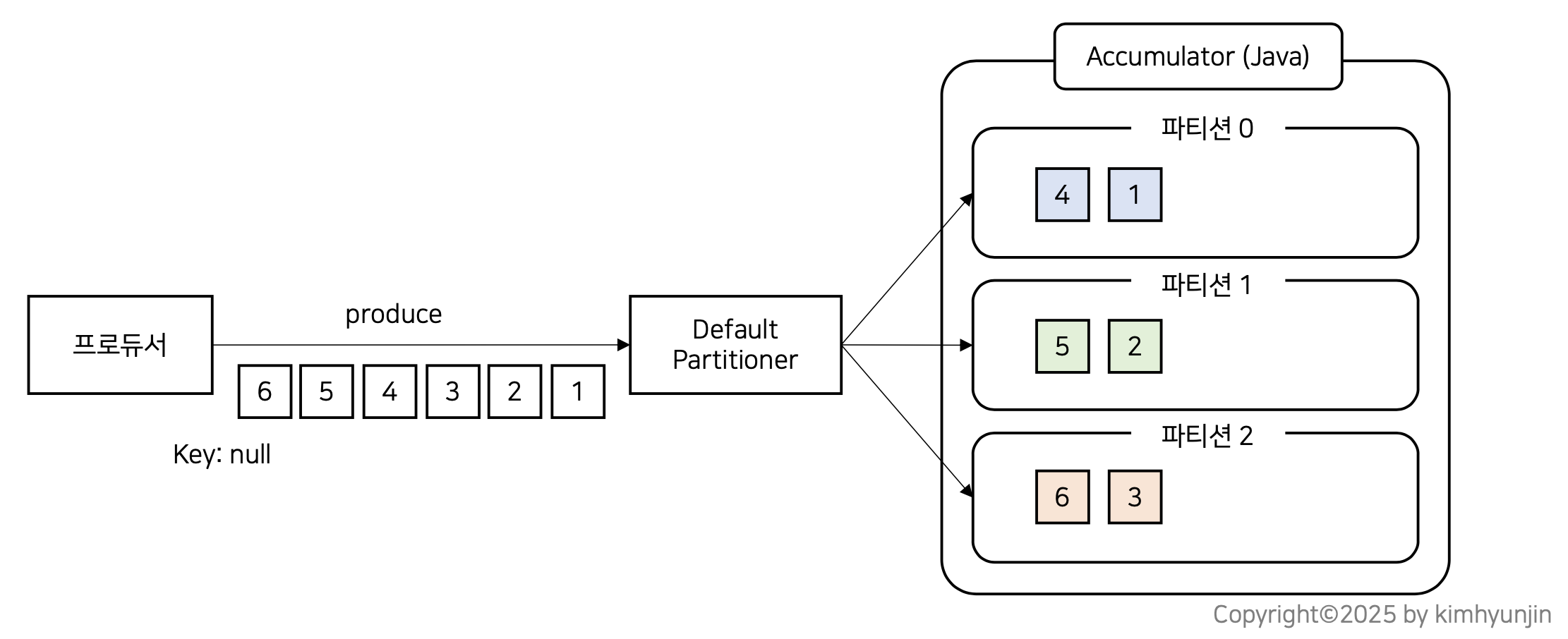
위의 그림은 라운드 로빈 방식이며, 단점이 존재한다.
Kafka 는 성능 향상을 위해 Accumulator에 레코드를 모았다가 전송하는 배치 전송이 기본 방식인데, 라운드 로빈 방식은 파티션을 골고루 채우다보니 개별 파티션이 꽉 찰 때까지 시간이 소요되는 단점이 존재한다
이를 개선하기 위해 아파치 카프카 2.4 에 Uniform Sticky 방식이 도입되었다.
스티키 방식은 랜덤하게 파티션을 하나 선택해서 먼저 채워나가는 방식이며, 그 다음 채워나갈 파티션 역시 랜덤하게 선택하게 된다.
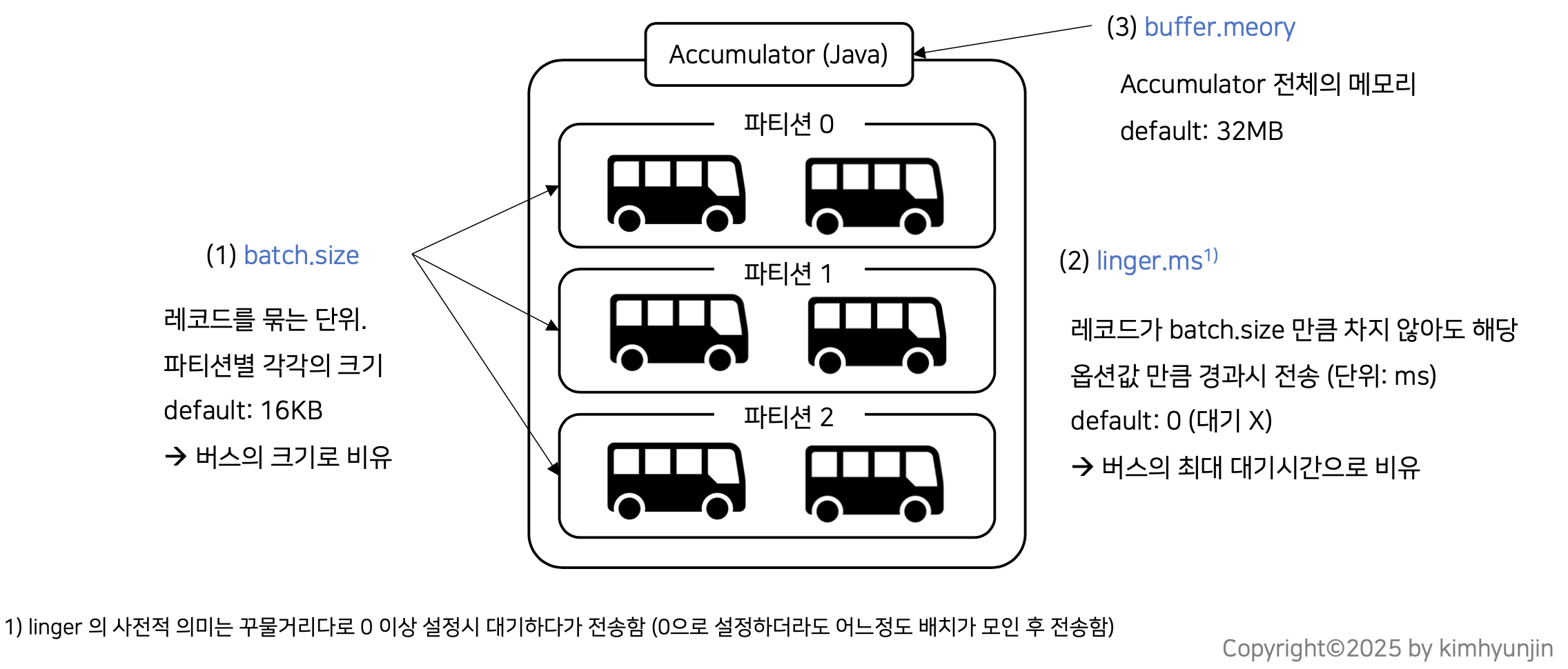
그럼 Accumulator는 브로커로 언제 전송될까?
아래 그림으로 이해해보면 각 파티션별로 버스가 있고 버스는 승객(record)가 모두 차야(batch.size) 출발하지만 승객이 모두 차지 않아도 일정 시간이 지나면 출발이 가능하다(linger.ms)
4-3) Confluent Kafka의 파티셔너
아파치 카프카와 Confluent Kafka 파티셔너를 비교한 그림을 보면 아래와 같다.

4-4) 압축 옵션 이해
Confluent 공식 사이트에 lz4 압축을 권고하고 있으며, gzip 압축은 권장하지 않고 있다.
이는 cpu 사용율이 높아지는 오버헤드 때문이다.
압축 사용시 Producer 성능(초당 전송율) 또한 증가하며 Consumer의 수신(초당 수신율) 성능도 향상된다.
참고로 Consumer는 압축된 메시지, 비압축된 메시지가 섞여 들어와도 문제없이 컨숨이 가능하다.
4-5) Producer 에러 처리 및 정합성 옵션
아래 그림과 같이 일부 설정값은 Confluent Python에서 제공하지 않거나 기본값이 다름에 주의하자.

아래 acks 옵션에서 주의해야할 점은 acks를 all로 설정하고, min.insync.replicas 옵션을 1로 설정을 하게 되면 acks 옵션을 1로 설정한 것과 같아지게 된다..
일반적으로 min.insync.replicas를 2 로 설정하는 것이 권장 된다.

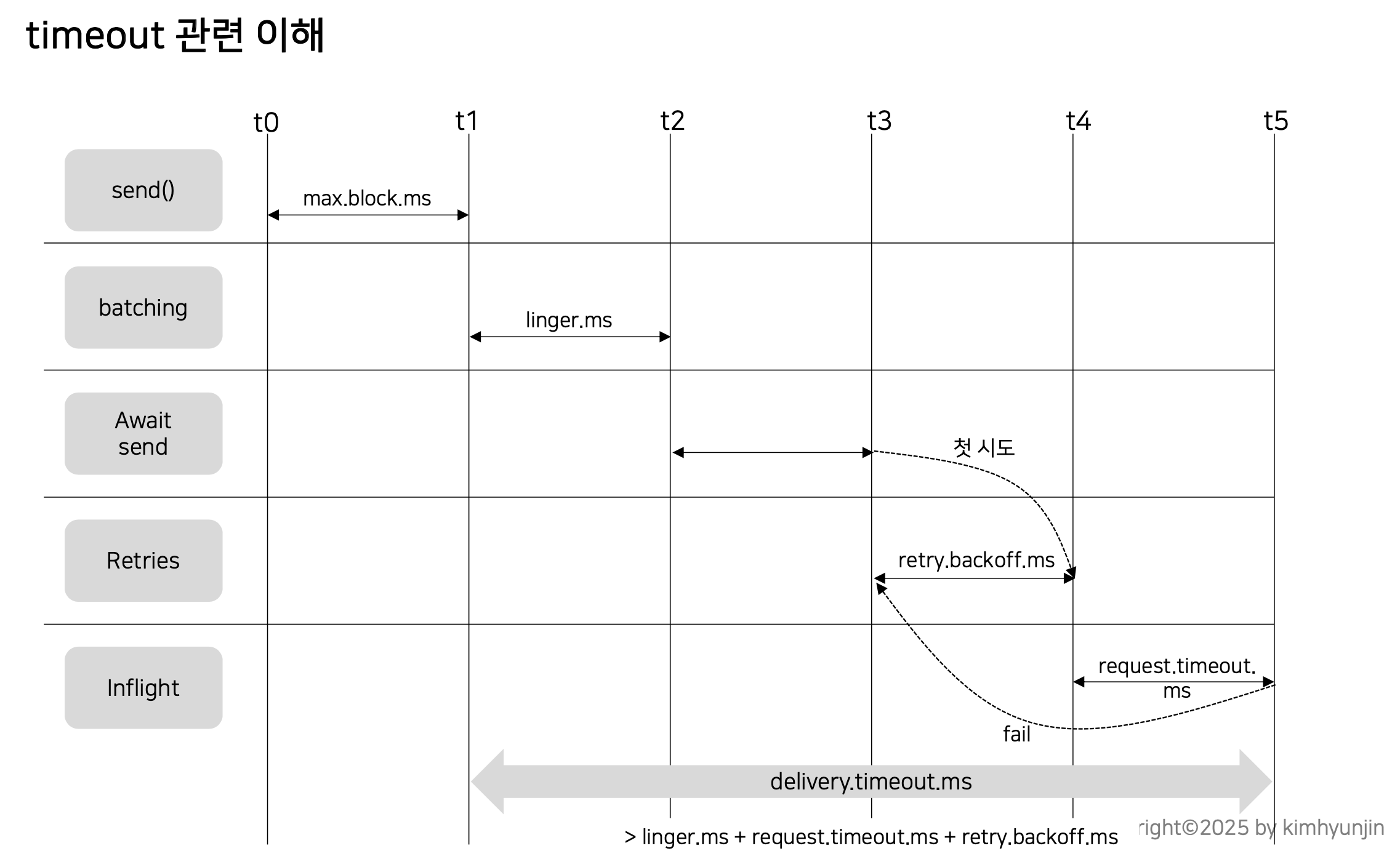
timeout 관련된 옵션을 조금 더 자세히 살펴보자.
send() 함수를 통해 데이터를 전달하게되면 accumulator에 데이터가 쌓인 후 데이터 묶음으로 브로커에 전달된다.
이때, accumulator에 메모리 공간이 없다면 max.block.ms 만큼 대기후 데이터를 넣게 된다.
그리고 accumulator에서 데이터 묶음(버스가 다 찬다면)을 채우면 브로커에 전달할 수도 있지만 다 채우지 않고도 linger.ms 지나면 브로커로 전달 된다.
브로커로 전달했는데 request.timeout.ms 만큼 기다려도 응답이 오지 않을 경우 실패로 간주하게 된다.
실패 했다면 재시도를 하는데 retry 하는 간격은 retry.backoff.ms 만큼 대기하면서 재처리를 지속적으로 시도하게 된다.
재처리를 지속적으로 한다면 t3 ~ t5 구간이 반복된다.
delivery.timeout.ms 는 send()를 호출하고 accumulator에 들어가고 부터 ack 응답을 최종적으로 받기 까지 걸린 시간이다.
이 설정값은 linger.ms + request.timeout.ms + retry.backoff.ms 를 합한 값보다 크게 설정을 해주어야 한다..
멱등성이라는 것은 여러번 실행해도 결과가 같은것을 의미하며, kafka producer 에서 멱등성이 있다는 것은 여러번 produce를 해도 브로커에 저장된 결과가 동일함을 의미한다.
아래 그림에서 batch data(0, 1, 2, 3, 4)는 데이터 묶음(버스)를 의미한다.
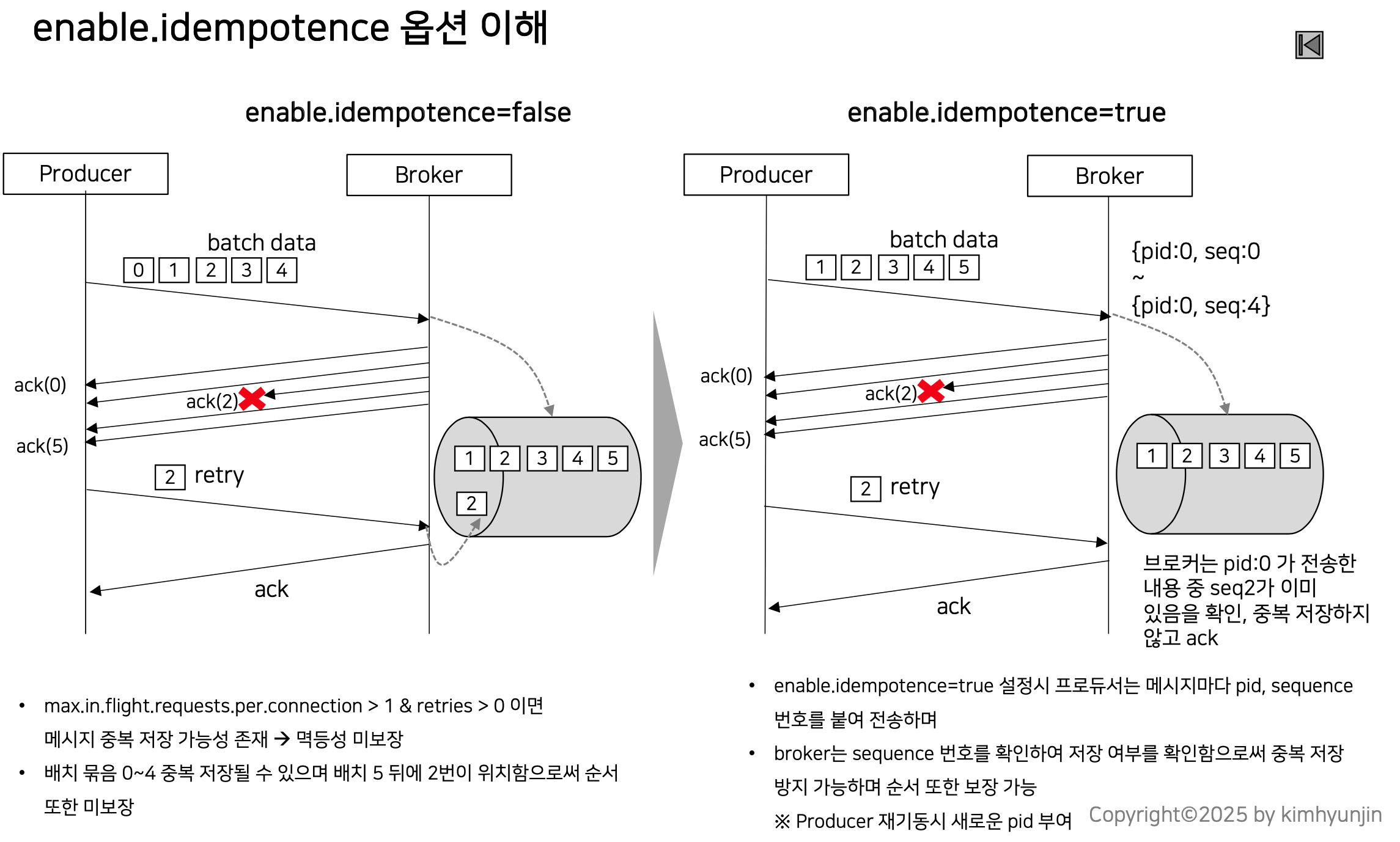
enable.idempotence 옵션을 true로 설정하게 되면 메시지마다 pid와 seq를 이용하여 중복 저장을 방지하고 순서를 보장한다.
단, 이 옵션을 true로 설정하려면 아래와 같은 조건이 필수적이다.
- max.in.flight.requests.per.connection 값을 5 이하로 설정
- retires를 0보다 크게 설정
- acks를 all로 지정
Reference
https://docs.aws.amazon.com/ko_kr/vpc/latest/userguide/VPC_NAT_Instance.html
https://docs.aws.amazon.com/ko_kr/vpc/latest/userguide/work-with-nat-instances.html
https://www.inflearn.com/course/kafka-spark-realtime-datalake/dashboard
https://docs.confluent.io/kafka-clients/python/current/overview.html