이번 글에서는 빅데이터 처리할 경우 사용하는 파일 포맷(Parquet, ORC, Avro)에 대해 살펴볼 예정이며 그 중에서도 Parquet에 대해 자세히 살펴보자.
Parquet, ORC, Avro의 공통점과 차이점은 아래와 같다.
공통점
- 기계가 읽을 수 있는 바이너리 포맷이며, 모두 하둡에 저장하는데에 최적화 되어 있다.
- 여러개의 디스크로 나뉘어질 수 있으며 이는 빅데이터의 분석처리에 용이하다.
- 스키마 파일을 가지고 있다.
차이점
Parquet와 ORC는 column 기반으로 저장하고, Avro는 row 기반으로 저장한다.
row 기반은 데이터를 쓸 때 용이하고, column 기반은 읽어서 분석해야 하는 경우 용이하다.
column 기반은 row 기반에 비해 압축률이 좋지만, 전체 데이터를 재구성하는데 시간이 오래 걸린다는 단점이 있다.
따라서 한번에 모든 필드를 접근해서 데이터를 읽고 쓰고자 할 때는 Avro 파일 포맷을 쓰는 것이 좋고, 특정 필드에만
반복적으로 접근해야 하는 경우 Parquet이나 ORC를 사용하는 것이 좋다.
1. Parquet(파케이)
데이터를 저장하는 방식 중 하나로 하둡생태계에서 많이 사용되는 파일 포맷이다.
빅데이터를 처리할 때는 많은 시간과 비용이 들어가기 때문에
빠르게 읽고, 압축률이 좋아야 한다.
이러한 특징을 가진 파일 포맷으로는 Parquet(파케이), ORC 가 있다.
Parquet가 압축률이 좋은 이유는 컬럼기반 저장포맷이기 때문이다.
먼저, 컬럼기반이 무엇인지 알아보자.
다음과 같은 데이터베이스를 이용하여 이해해보자.
행 기반으로 저장되는 건 아래와 같이 저장된다.
열 기반으로 저장되는 건 아래와 같이 저장 된다.
그럼 왜 열 기반으로 저장되는 것이 압축률이 더 좋을까?
같은 컬럼에는 종종 유사한 데이터가 나열된다.
특히 같은 문자열의 반복은 매우 작게 압축할 수 있다.
데이터의 종류에 따라 다르지만, 열 지향 데이터베이스는 압축되지 않은 행 지향 데이터 베이스와
비교하면 1/10 이하로 압축 가능하다.
또한, 데이터를 전체 컬럼 중에서 일부 컬럼을 선택해서 가져오는 형식이므로
선택되지 않는 컬럼의 데이터에서는 I/O가 발생하지 않게 된다.
즉 컬럼 기반 포맷은 같은 종류의 데이터가 모여 있으므로 압축률이 더 높고,
일부 컬럼만 읽어 들일 수 있어 처리량을 줄일 수 있다.
데이터 분석에서는 종종 일부 컬럼만이 집계 대상이기 때문에, 이렇게 열 기반으로 압축하면 필요한 컬럼만을 빠르게 읽고 집계할 수 있다.
그렇다면 열 기반으로만 저장하는게 무조건 좋은게 아닌가?
MySQL의 경우 대표적인 행 기반 저장 방식의 데이터베이스이다.
행 기반 데이터베이스는 매일 발생하는 대량의 트랜잭션을 지연 없이 처리하기 위해
데이터 추가를 효율적으로 할 수 있도록 하는 것이 행 지향 데이터베이스의 특징이다.
즉, 새로운 레코드를 추가할 경우 끝부분에 추가되기 때문에 고속으로 쓰기가 가능하다.
1-1) Parquet 구조
파케이 파일은 header, 하나 이상의 block, footer 순으로 구성된다.
header와 footer는 meta 정보이며 1개씩만 존재한다.
block은 list 형식이며 여기에 실제 N 개의 데이터가 저장된다.
여기서 block은 hdfs의 block 이며, 한번에 읽을 때 단위를 의미한다.
Parquet는 데이터를 저장하기 위해 hierarchical structure를 사용한다.
- Row Groups
- Columns
- Pages
Parquet 파일 하나는 1개 이상의 Row group이 있고,
Row group 은 column 별로 저장되어 있다.
Row group 단위로 데이터를 읽고 쓰는 것이 가능하며, 이는 스캔 속도를 높이는데 기여한다.
일반적으로 Row group은 512MB ~ 1GB 사이로 설정하는 것이 권장되며, parquet.block.size 옵션으로 수정할 수 있다.
column chunk는 여러 개의 page로 구성되며, 실제 데이터와
인코딩, 압축 정보 등이 저장된다.
page 단위로 압축을 적용하고, page 헤더의 통계 정보를 담아서 pruning에 활용할 수도 있다.
각 페이지는 동일한 컬럼의 값만 포함하고 있다.
따라서 페이지에 있는 값은 비슷한 경향이 있기 때문에 페이지를 압축할 때 매우 유리하다.
데이터의 가장 최소 단위인 페이지에는 동일 컬럼의 데이터만 존재한다. 그래서 인코딩/압축을 할 때, 페이지 단위로 수행하면 된다.
위 구조가 머리속에 그려지면 파케이 파일을 만들 때 아래 설정 값이 이해된다.
1-2) 파케이 파일 확인
생성된 파케이 파일을 확인하기 위해 duckdb를 사용할 수 있다.
// 설치
$ brew install duckdb
$ duckdb
$ D * from read_parquet('/Users/jang-won-yong/Downloads/cities.parquet') limit 3
1-3) 장단점
Advantages
- Efficient Compression: 고배율로 압축이 가능하다.
- Optimized for Queries: 컬럼 기반으로 읽을 경우 효율적이다.
- Integration: Spark, Hive, Impala 와 같은 빅데이터 프레임워크와 호환이 뛰어나다.
Disadvantages
- Write Overhead: CSV 와 같은 간단한 파일 포맷과 비교해서 더 많은 CPU 자원을 사용한다.
- Not Human-Readable: 바이너리 포맷이기 때문에 사람이 분석 및 디버깅이 어렵다.
- Small Files Issue: 많은 small file 을 만들어내는 구조라면 쓰기 성능에 영향을 끼칠 수 있기 때문에 큰 파일이 생기는 구조일때 사용해야 한다.
2. ORC
ORC(Optimized Row Columnar)는 컬럼 기반의 파일 저장 방식으로 Hadoop, Hive, Pig, Spark 등에 적용이 가능하다.
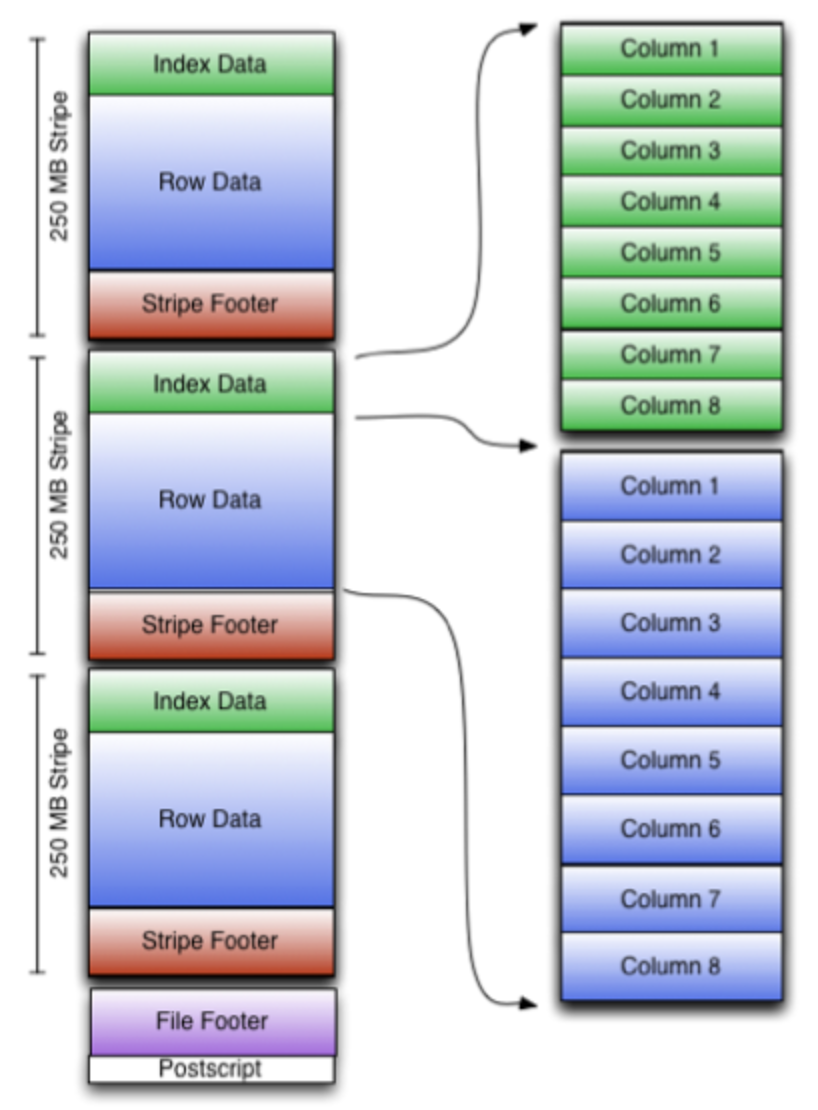
parquet 에서 row group 단위로 하나의 파일에서 나눠서 읽을 수 있는 역할을 orc는 stripe 라는 이름으로 제공한다.
2-1) ORC 파일 확인
ORC 파일 확인하기 위해서 orc-tools를 이용하여 확인 가능하다.
링크에서 orc-tools-1.9.2-uber.jar 를 다운 받은 후 사용할 수 있다.
2-2) ORC 장단점
Advantanges
- ORC는 Apache Hive를 위해 설계되었으며, Hive에 최적화되어 있다.
- High Compression: 일반적으로 Parquet에 비해 우수한 압축률로 알려져 있다.
Disadvantages
- Parquet에 비해 다양한 데이터 처리 엔진에서의 호환성이 낮을 수 있다.
- 중첩 데이터의 처리에서 Parquet만큼 유연성을 제공하지 못한다.
3. Apache Avro
Apache Avro 는 row 기반으로 저장되는 포맷이다.
3-1) Avro 장단점
Advantages
- Schema Evolution: 스키마는 JSON 포맷을 사용하기 때문에 변경에 대해 유연하다.
- Fast: real time과 같이 빠르게 처리되는 processing에 대해서 serializing and deserializing data 가 효율적이다.
- Parquet 및 ORC 에 비해 압축 효율은 떨어지지만 쓰기 속도는 더 빠르다.
Disadvantages
- Human Readability: 데이터 파일 자체는 바이너리 포맷이기 때문에 사람이 읽기 어렵다.
- Less Optimized for Queries: row 기반이기 때문에 parquet 포맷과 같이 컬럼 기반으로 분석하는 경우는 비효율적이다.
- 압축 비율이 Parquet, ORC 보다 낮다.
4. 파일 압축(gzip, snappy)
4-1) Gzip
- snappy 보다 더 많은 cpu 리소스를 사용하지만 더 높은 압축을 할 수 있다.
- 높은 압축률을 제공하지만, 압축/해제 속도가 느리다
- 주로 백업 데이터나 데이터 전달 용도로 사용한다.
- 실시간 쿼리가 필요한 분석 작업에는 잘 사용되지 않는다.
파일 형식 중 하나인 tar 와 함께 .tar.gz 형식으로 자주 사용된다.
4-2) Snappy
- 가장 많이 사용되는 압축 방식이며, 빠른 압축 및 해제 속도를 제공한다.
4-3) Zstandard (ZSTD)
- gzip과 비슷한 압축률을 제공하지만 압축/해제를 할 때는 더 빠르다.
- 대규모 데이터 레이크에서 저장 비용 절감이 필요한 경우 사용한다.
Reference
https://devidea.tistory.com/92
https://amazelimi.tistory.com/entry/File-Format-For-Big-Data-Parquer-vs-ORC-vs-Avro-LIM
https://amazelimi.tistory.com/78
https://blog-tech.tadatada.com/2018-05-23-parquet-and-spark