현재 업무에서 VictoriaMetrics 기반 사내 플랫폼이 제공되고 있고, 여기에 Airflow 메트릭을 scrape해 이 플랫폼으로 remote_write를 하기 위해 Prometheus가 사용되고 있다.
Airflow -> statsd_exporter -> prometheus -> 사내 플랫폼(VictoriaMetrics)
레거시 시절부터 이어져 온 구성인데, 단순히 Prometheus가 scrape 후 remote_write만 하는 역할임에도 전체 TSDB를 함께 운영하기 때문에 불필요한 메모리/디스크 부담이 발생한다.
또한, Prometheus가 Virtual Machine 위에 구성이 되어 있기 때문에 이를 K8s의 Pod 형태로 관리하려고 한다.
이처럼 Prometheus가 단순히 수집, 전달만 필요한 경우라면 굳이 전체 TSDB를 운영할 이유가 없으므로, 이 글에서는 vmagent를 대안으로 함께 검토해보려고 한다.
먼저, Airflow Astro CLI를 통해서 빠르게 로컬환경을 구성하고, Airflow 에서 발생하는 메트릭 수집 및 grafana 대시보드를 구성하는 컴포넌트들을 구성해보며, 동작방식을 자세히 살펴볼 예정이다.
1. Astro CLI 를 이용하여 환경 구성하기
Astro CLI는 Astronomer 에서 만든 CLI로, Airflow를 로컬에서 쉽게 띄우고 DAG를 테스트할 수 있는 도구 이다.
# brew install astro does not support --without-podman and will install Podman
$ brew tap astronomer/tap
$ brew install astronomer/tap/astro --without-podman
$ brew install astro
$ astro version
처음 Astro CLI를 이용하여 환경을 구성하게 되면 Astro CLI에 기본 설정된 astro runtime이 지원하는 가장 최신 버전으로 프로젝트가 생성된다.
하지만 특정 버전의 Airflow로 프로젝트 생성이 필요하다면 아래와 같이 진행하면 된다.
$ astro dev init --airflow-version 3.1.1
# 또는 아래와 같이 astro runtime 버전 지정이 가능하다.
# release note 에서 지원하는 airflow 버전을 확인하여 runtime version을 사용하면 된다.
# https://www.astronomer.io/docs/astro/runtime-release-notes
$ astro dev init --runtime-version 4.1.0
그 이후 아래와 같이 실행 및 중지가 가능하다.
$ astro dev start
$ astro dev stop
$ astro dev restart
# 신규로 생성된 파일에 대해서 기본적으로 5분마다 스캔(반영)되므로 테스트를 진행할 때 해당 명령으로 빠르게 신규 파일 UI에 반영
$ astro dev run dags reserialize
또한, DAG 단위 테스트를 하여 개발한 코드가 정상 동작하는지 빠르게 확인할 수 있다.
# DAG를 구문 분석하여 기본 syntax나 import 오류가 없는지, Airflow UI에서 성공적으로 렌더링할 수 있는지 확인
$ astro dev parse
# tests 디렉토리 안에 있는 모든 테스트를 진행
$ astro dev pytest
이제 astro dev start 를 이용하여 컨테이너를 실행하면 airflow 와 관련된 컨테이너가 5개 실행된다.
- scheduler
- scheduler, local executor, worker process 가 수행되는 container
- postgres
- Meta DB를 제공하는 PostgreSQL 이 수행되는 Container
- triggerer
- Async Sensor를 위한 Async Event Loop가 수행되는 Container
- api-server
- API Server/Web UI가 수행되는 container
- dag-processor
- DAG 파일을 Parsing/Serialization 적용하는 dag processor 수행되는 container
이제 Astro project 내 주요 서브 디렉토리와 환경 파일에 대해서 이해해 보자.
아래 디렉토리 구조에서 dags는 DAG Python 파일들을 위치 시키는 디렉토리이며, include는 Astro에서 DAG Python 파일 이외에 custom 모듈들을 import하기 위해 지정한 디렉토리이다.
.
├── dags/
├── include/
├── plugins/
├── tests/
├── Dockerfile
├── requirements.txt
├── packages.txt
├── airflow_settings.yaml
└── docker-compose.override.yml
여기서 중요한 것은 dags, include, plugins 디렉토리를 각 Airflow 컨테이너에 bind mount 해서 동일 파일을 공유하도록 설정되어 있다.
즉, scheduler, api server, dag processor 컨테이너가 동일한 dags 파일들을 가지고 있으며 scheduler 컨테이너 내에 dags 파일을 수정하면 다른 컨테이너에 존재하는 dags 파일도 동일하게 변경된다.
2. StatsD
StatsD는 어플리케이션이 메트릭을 UDP로 쏘는 경량 push 프로토콜이다.
Airflow도 이 StatsD 클라이언트 역할을 하며, [metrics] 설정을 켜면 메트릭을 StatsD 포맷으로 직접 내보낸다.
다만 Prometheus가 pull(scrape) 방식이라 StatsD의 push와 직접 맞지 않기 때문에, 보통 statsd_exporter 를 중간에 두어 push로 받은 메트릭을 Prometheus가 scrape할 수 있는 형태로 변환한다.
즉 원조 StatsD 데몬을 따로 띄우는 것이 아니라, statsd_exporter가 그 수신 자리를 대신하면서 push -> pull 변환 다리 역할을 한다.
UDP는 보낸 데이터(패킷)가 도착했는지 확인하지 않는 fire-and-forget 방식 반면, Prometheus는 메트릭을 가져갈 때 TCP 기반으로 보낸 데이터의 도착여부를 확인(ACK) 하고, 빠진건 다시 보내고, 순서도 맞추는 방식
StatsD가 UDP로 보내는 이유는 push 방식이기 때문이며, 어플리케이션에서 초당 수천번 이상 발생하는 메트릭을 TCP처럼 매번 연결, 도착 확인, 재전송을 하기는 어렵기 때문이다.
반면, Prometheus의 경우 pull 방식이라, 일정한 주기에 맞춰서 한번에 가져오는 작업이기 때문에 TCP 로 수집한다.

statsd_exporter 는 push로 들어온 증분 이벤트들을 받아 메모리에 누적, 집계해 현재 상태로 보관하고 그 전체를 /metrics에 스냅샷으로 노출한다.
3. Prometheus vs vmagent
수집기는 Prometheus 를 선택하는 방안과 vmagent 와 VictoriaMetrics 를 같이 사용하는 방안을 비교해 볼 수 있다.
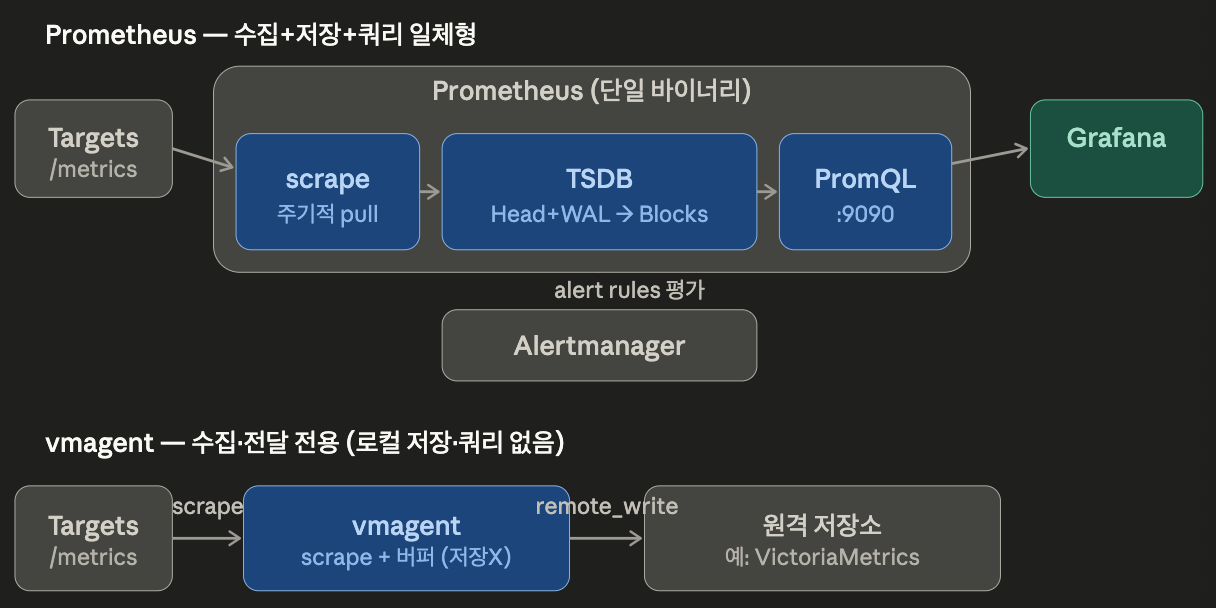
3-1) Prometheus
Prometheus는 단일 바이너리가 scrape(pull), TSDB 저장, PromQL 쿼리와 alerting rule 평가 등의 기능을 모두 제공한다.
pull 모델이라 정해진 간격으로 statsd_exporter 의 /metrics 를 HTTP(TCP)로 scrape해 그 순간의 완전한 스냅샷을 신뢰성 있게 받아온다.
받은 값을 시계열 DB로 저장하고, PromQL로 조회한다.
TSDB는 Time Series DataBase, 즉 시계열 전용 저장 엔진이다.
PromQL 쿼리가 들어오면 Prometheus는 이 TSDB를 읽어서 응답한다.
Prometheus의 TSDB는 Mysql 등 처럼 따로 설치해서 띄우는 별도 DB 서버가 아니고, Prometheus 바이너리 안에 내장된 저장 엔진이며, 데이터를 Prometheus가 도는 머신 디스크에 파일로 직접 쓴다.
위 그림에서 Head 는 메모리를 의미하며, 가장 최근 데이터(대략 최근 2시간)를 메모리에 들고 있는다.
WAL(Write-Ahead Log, 디스크) 는 Head에 올리는 것과 동시에 모든 데이터를 디스크에 순차적으로 기록한다.
Prometheus가 죽었을 때 메모리는 날라가지만 디스크에 적어둔 WAL을 재시작 때 다시 읽어서 Head를 복구한다.
Block(디스크, 불변) 은 약 2시간 마다 Head에 쌓인 데이터를 불변 Block으로 디스크에 영속화 한다.
한 Block은 압축된 데이터, 인덱스, 메타데이터로 이뤄지고, 고정된 시간 범위를 담는다.
Block이 만들어지면 그에 해당하는 Head, WAL 부분은 정리된다.
Block은 시계열 데이터 단위이며, 각 Block은 특정 시간 범위를 담고 그 범위의 쿼리에 필요한 모든 데이터를 포함한다.
Head 는 가장 최근 데이터를 받아 저장하는 인메모리 컴포넌트이다.
Prometheus를 scrape + remote_write로만 사용한다고 해도 일반 Prometheus 서버라면 내부적으로 TSDB를 그대로 운영할 것이다.
즉, 쓰지도 않는 로컬 저장, 쿼리 기능에 자원을 쓰고 있는 상태일 것이다.
이러한 경우 vmagent로 전환 하는 방법이 있을 것이고, Prometheus를 Agent 모드로 돌리는 방법도 존재한다.
Agent 모드는 remote_write 용도에 최적화되어 쿼리, alert rule, 로컬 저장을 비활성화하고 맞춤형 TSDB WAL로 대체하며, scrape 로직, 서비스 디스커버리는 그대로 유지된다.
일반 서버모드의 TSDB는 Head, WAL, 영속 Block, 쿼리용 인덱스 등으로 이루어지는데, Agent 모드는 이 중 Block 생성과 쿼리 인덱스를 아예 만들지 않고 WAL 만 남기게 된다.
서비스 디스커버리(service discovery)는 Prometheus가 무엇을 scrape할지(타깃 목록)을 알아내는 방법이다. 가장 단순하게 static_configs 로 타깃 주소를 직접 나열하는 방식을 예로 들 수 있다.
기존 레거시 Prometheus에서 alert rule이나 recording rule을 사용하고 있다면, vmagent는 규칙 평가에 대한 기능을 제공하지 않기 때문에 추가로 vmalert 등을 함께 도입을 고려해야 한다.
Prometheus Agent 모드도 마찬가지로 recording rule과 alerting 기능은 제공하지 않는다.
또한, Prometheus의 로컬 UI(:9090)나 로컬 데이터로 디버깅하는 등을 기존에 사용했다면 vmagent 는 이러한 기능을 제공하지 않기 때문에 이 점도 감안해야 할 수 있다.
3-2) vmagent + VictoriaMetrics
다른 방안은 수집과 저장을 분리하는 방식이며, vmagent 와 VictoriaMetrics 를 사용해볼 수 있다.
VictoriaMetrics
VictoriaMetrics는 Prometheus 호환 API를 제공하면서도 높은 압축 효율과 대규모 클러스터링, 장기 보관을 지원한다.
remote_write로 보낸 데이터를 받아 저장하고 MetricsQL로 조회한다.
vmagent
경량 수집 에이전트이며 쿼리 가능한 로컬 TSDB를 운영하지 않고, scrape 후 remote_write로 외부 저장소에 전달하는 역할을 한다.
scrape 하는 행동(HTTP/TCP)는 Prometheus와 똑같지만, 받은 데이터를 자기 디스크에 영구 저장(TSDB) 하지 않고 remote_write(HTTP/TCP)로 원격 저장소에 넘긴다.
수집 부분만 담당하는 경량 에이전트로 이해하며 된다.
remote_write 란 수집한 메트릭을 다른 네트워크 너머의 다른 저장소로 보내는 표준방식이다.
참고로, vmagent 는 pull 방식 뿐만 아니라 push 방식도 지원한다.
vmagent와 Prometheus 둘 다 타깃(/metrics)을 scrape 하고, 여러 원격 저장소로 데이터를 보낼 수 있다.
하지만, Prometheus의 remote_write는 scrape한 샘플을 로컬 TSDB와 WAL(Write-Ahead Log)에 쓰고, 그 WAL을 다시 읽어 원격으로 보낸다.
그래서 remote_write을 사용하게 되면 Prometheus 메모리 사용량이 증가하는 반면, vmagent는 TSDB 저장, 쿼리 없이 수집, 전달만 하기 때문에 부담이 적다.
vmagent가 Prometheus보다 훨씬 적은 RAM, CPU, 디스크 IO, 네트워크 대역폭을 쓴다고 알려져있다. Prometheus보다 가벼운 근본 이유가 TSDB를 운영하지 않기 때문이다.
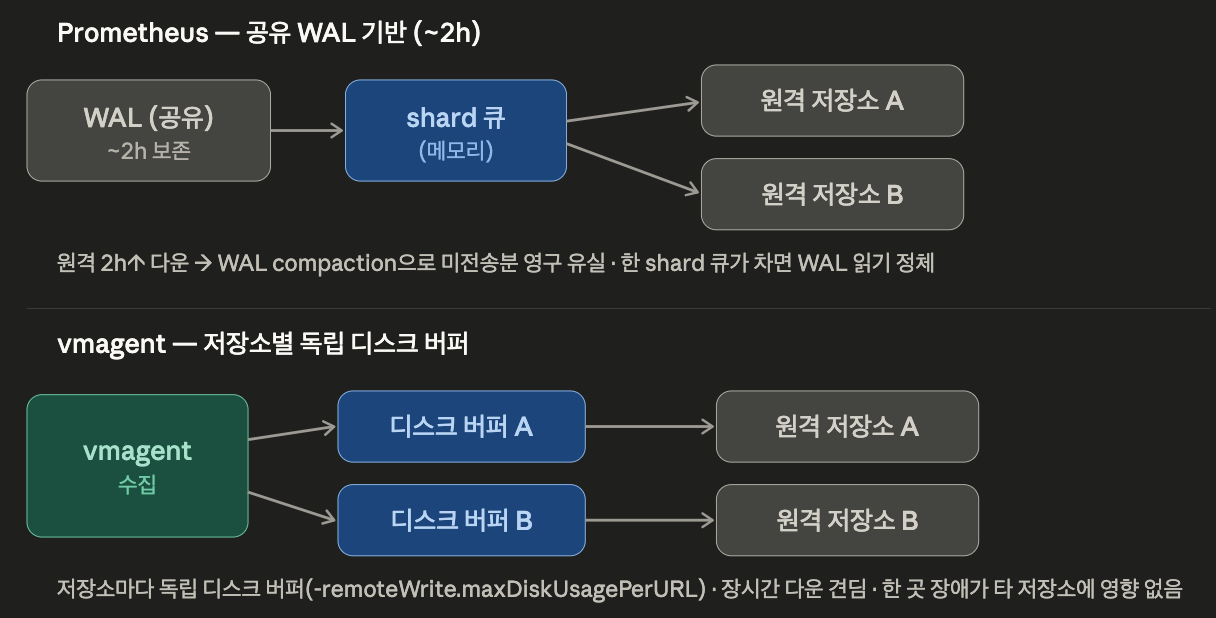
또한, vmagent를 사용할 때 장점은 버퍼링이 더 안전하다는 것이다.
Prometheus Agent 모드든 일반 서버든 Prometheus의 remote_write는 WAL 기반이라, 원격 대상이 가용하지 않을 때 재시도를 위해 샘플을 로컬에 보관하지만 그 보관은 기본 2시간(WAL 2h)이다.
즉, VictoriaMetrics가 2시간 넘게 다운되면 미전송분이 유실될 수 있다.
반면, vmagent는 원격 저장소마다 독립 디스크 버퍼(remoteWrite.maxDiskUsagePerURL) 를 둬서 디스크를 넉넉히 주면 그보다 훨씬 긴 다운도 견딘다.
vmagent 는 평상시엔 메모리로 메트릭을 흘려보내고, 원격 저장소가 느려지거나 끊키면 디스크로 버퍼링한다.
다만, vmagent의 디스크 버퍼도 무한은 아니며, 설정한 한도에 도달하면 가장 오래된 데이터부터 FIFO로 폐기한다.
마지막으로 vmagent는 sharding 을 위한 clusterMode를 제공함으로써, 트래픽을 분산하여 처리할 수 있다.
clusterMode:
enabled: true
replicas: 3 # Number of VMAgent pods for sharding
위 예시와 같이 clusterMode를 활성화하면 N개 pod가 타깃을 나눠서 scrape 한다.
각 pod에 고유 번호(memberNum, StatefulSet pod 순번에서 가져옴)가 붙고, 각 pod 별로 전체 타깃의 1/N 씩만 담당하게 된다.
하지만 현재 statsd_exporter 를 1개만 사용하고 있기 때문에, clusterMode 를 활성화 해도 의미 없다.
타깃 1개는 하나의 pod에만 배정되기 때문에 나머지 pod는 놀게된다.
3-3) Prometheus, vmagent High Availability(HA)
Prometheus, vmagent 모두 HA는 동일 설정 인스턴스를 2개 이상 띄워 같은 타깃을 scrape하게 하는 이중화로 달성하게 된다.
즉, Raft 같은 합의 기반 HA가 아니라, redundancy 기반 HA 이다.
인스턴스가 죽어도 나머지가 계속 scrape하므로 수집 공백이 생기지 않고, 두 인스턴스가 보낸 중복 데이터는 다운스트림인 VictoriaMetrics가 제거한다.
VictoriaMetrics는 -dedup.minScrapeInterval 옵션을 제공한다.
장애 복구 메커니즘에서 아래와 같이 차이가 발생한다.
첫째, 프로세스가 죽었다 살아나는 로컬 복구이다.
vmagent는 복원할 TSDB 자체가 없고, -remoteWrite.tmpDataPath의 persistent queue(디스크 버퍼)에 쌓인 미전송분만 재전송하는 방식이다.
Prometheus는 서버 모드의 경우와 Agent 모드 각각 복구 방식이 조금 다르다.
- 서버 모드는 일반 TSDB를 운영하므로, 재시작 시 WAL을 재생해 메모리의 Head를 죽기 직전 상태로 재구성한다.
- remote_write를 함께 쓰고 있었다면 WAL을 이용하여 미전송분 전송도 같이 재개한다.
- 복구 대상이 쿼리 가능한 내부 시계열 상태 라는게 핵심이다.
- Agent 모드는 쿼리, 로컬 저장, 영속 Block, 쿼리 인덱스를 모두 비활성화하고 맞춤형 WAL만 남긴 형태이다.
- 즉, 되살릴 Head나 TSDB가 애초에 없다. 그래서 Agent 모드의 WAL은 순수하게 remote_write 전송하기 위한 복구용으로 사용된다.
Prometheus의 Agent 모드는 vmagent의 persistent queue 복구와 성격이 비슷하며, 둘 다 되살릴 내부 쿼리 상태는 없고, 디스크에 남은 미전송분만 다시 보낸다는 구조이다.
차이라면 그 미전송분을 담는 그릇이 Agent 모드는 WAL(기본 2시간)이고, vmagent는 persistent queue(maxDiskUagePerURL 로 정한 디스크 용량까지) 라는 점이다.
여기서 의문을 가질 수 있는 부분이 Spark Streaming의 경우 checkpoint 등을 통해 프로세스가 죽었다가 복구했을 때 어디서부터 처리할지에 대한 정보가 있는데 Prometheus, vmagent도 이러한 메커니즘이 존재하는지에 대한 부분이다.
Prometheus와 vmagent의 scrape은 이어서 받는 스트림이 아니라 매번 현재 상태 전체를 새로 찍는 스냅샷이라는 점이다.
statsd_exporter 같은 타깃의 /metrics는 호출할 때마다 지금 이순간의 모든 메트릭 값 전체를 통째로 리턴한다.
즉, redendancy HA 를 통해 한 프로세스가 죽었을 때 생기는 공백을 다른 인스턴스가 scrape 하여 가용성을 유지한다.
둘때, 저장소(VictoriaMetrics)가 오래 다운됐을 때 오래 버티는 능력(버퍼링 안정성)이며 이는 위에서 설명한 내용과 동일하다.
4. Grafana
Grafana는 VictoriaMetrics(또는 Prometheus)를 데이터소스로 연결해 메트릭을 쿼리하고 대시보드로 시각화하는 도구이다.
5. 로컬 모니터링 파이프라인 구성하기
Reference
https://www.astronomer.io/docs/astro/cli/install-cli
https://medium.com/@kade.ryu/2024%EB%85%84-%EA%B0%80%EC%9E%A5-%EC%89%BD%EA%B2%8C-airflow-%EB%A1%9C%EC%BB%AC-%ED%99%98%EA%B2%BD-%EC%85%8B%EC%97%85%ED%95%98%EB%8A%94-%EB%B0%A9%EB%B2%95-5612cb2d56aa
https://medium.com/@ayusshhh0/migration-from-prometheus-to-vmagent-for-better-performance-and-memory-optimization-8682daeaf659